# 双越前端面试 100 题
记录几个有意思的算法题
- 数组是连续空间,要慎用 splice、unshift 等 API,时间复杂度是 O(n)起步
# 浮动 0 到数组的一侧
// 双指针法,j指向第一个0,原地交换,实际上是把非0的值移到左侧
function floatNum(arr) {
const length = arr?.length;
if (length <= 1) return arr;
let i = 0,
j = -1;
while (i < length) {
if (arr[i] === 0) {
// 先找到第一个0
if (j < 0) {
j = i;
}
}
if (arr[i] !== 0 && j >= 0) {
// 交换0到数组右侧,非0的到左侧
const temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
// 交换之后,j要往右移动一位
j++;
}
i++;
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 求相同连续字符串的最大长度
- 双指针法,时间复杂度 O(n)
function maxLen(str) {
const res = { str: "", length: 0 };
const length = str?.length;
if (length <= 1) return { str, length };
let i = 0,
j = 0,
tempLen = 0;
while (j < length) {
if (str[i] === str[j]) {
tempLen++;
}
if (str[i] !== str[j] || j === length - 1) {
if (tempLen > res.length) {
res.length = tempLen;
res.str = str[i];
}
tempLen = 0;
if (j < length - 1) {
i = j;
j--; // j在这次循环之后会++,所以要先--,然后i才和j相等。
}
}
j++;
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 双循环,跳步,使时间复杂度降到 O(n)
function maxLen(str) {
const res = { str: "", length: 0 };
const length = str?.length;
if (length <= 1) return { str, length };
let maxLength = 0;
for (let i = 0; i < length; i++) {
maxLength = 0;
for (let j = i; j < length; j++) {
if (str[i] === str[j]) {
maxLength++;
}
// 如果不相等或者已经匹配到最后
if (str[i] !== str[j] || j === length - 1) {
if (maxLength > res.length) {
res.length = maxLength;
res.str = str[i];
}
if (i < length - 1) {
i = j - 1; // 跳步
}
break;
}
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 反转链表
// 迭代
var reverseList = function (head) {
if (head === null || head.next === null) {
return head;
}
let prev = null,
cur = head;
while (cur !== null) {
const next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return prev;
};
// 递归
var reverseList = function (head) {
// 递归终止条件
if (head == null || head.next == null) return head;
// 递
const newHead = reverseList(head.next);
// 归:这时候右边已经反转的node和左边未反转的node相邻的两个节点是互相指向对方的状态,此时的head指向递归调用栈这一层的node
head.next.next = head;
head.next = null;
return newHead;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 删除链表中所有给定的某个值
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
- 递归
var deleteNode = function (head, val) {
if (!head) return head;
head.next = deleteNode(head.next, val);
return head.val === val ? head.next : head;
};
2
3
4
5
# 删除链表倒数第 N 个节点
- 假设 N
<=链表长度。通过快慢指针,快指针先走 n+1 步,使快慢指针之间有 N 个节点,然后两个指针一起右移直到快指针指向 null,这时慢指针的下一个节点就是要删除的节点,让 slow.next=slow.next.next 即可,中间要注意删除 head 节点的情况。
var removeNthFromEnd = function (head, n) {
let slow = head,
fast = head;
// 先让 fast 往后移 n 位
while (n--) {
fast = fast.next;
}
// 如果 n 和 链表中总结点个数相同,即要删除的是链表头结点时,fast 经过上一步已经到外面了
if (!fast) {
return head.next;
}
// 然后 快慢指针 一起往后遍历,当 fast 是链表最后一个结点时,此时 slow 下一个就是要删除的结点
while (fast.next) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return head;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 寻找链表中点
- 通过快慢指针寻找链表中点:快指针每次移动 2 步,慢指针每次移动 1 步
function findCenter(head) {
let slower = head,
faster = head;
while (faster && faster.next != null) {
slower = slower.next;
faster = faster.next.next;
}
// 如果 faster 不等于 null,说明是奇数个,slower 再移动一格
if (faster != null) {
slower = slower.next;
}
return slower;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 前序遍历判断回文链表
- 利用链表的后序遍历,使用函数调用栈作为后序遍历栈,来判断是否回文
var isPalindrome = function (head) {
let left = head;
function traverse(right) {
if (right == null) return true;
// 这里会递归到最后一个node,然后一层一层往前
let res = traverse(right.next);
// 记录左右指针是否相等,初始值是tailNode.next===null,也就是true
res = res && right.val === left.val;
// 左边的指针每次要右移一个
left = left.next;
return res;
}
return traverse(head);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
- 通过 快、慢指针找链表中点,然后反转链表,比较两个链表两侧是否相等,来判断是否是回文链表
var isPalindrome = function (head) {
// 反转 slower 链表
let right = reverse(findCenter(head));
let left = head;
// 开始比较
while (right != null) {
if (left.val !== right.val) {
return false;
}
left = left.next;
right = right.next;
}
return true;
};
function findCenter(head) {
let slower = head,
faster = head;
while (faster && faster.next != null) {
slower = slower.next;
faster = faster.next.next;
}
// 如果 faster 不等于 null,说明是奇数个,slower 再移动一格
if (faster != null) {
slower = slower.next;
}
return slower;
}
function reverse(head) {
let prev = null,
cur = head,
nxt = head;
while (cur != null) {
nxt = cur.next;
cur.next = prev;
prev = cur;
cur = nxt;
}
return prev;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 合并 2 个升序链表
// 迭代1
function merge(l1, l2) {
if (l1 == null && l2 == null) return null;
if (l1 != null && l2 == null) return l1;
if (l1 == null && l2 != null) return l2;
let newHead = null,
head = null;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
if (!head) {
newHead = l1;
head = l1;
} else {
newHead.next = l1;
newHead = newHead.next;
}
l1 = l1.next;
} else {
if (!head) {
newHead = l2;
head = l2;
} else {
newHead.next = l2;
newHead = newHead.next;
}
l2 = l2.next;
}
}
newHead.next = l1 ? l1 : l2;
return head;
}
// 迭代2
function merge(l1, l2) {
if (l1 == null && l2 == null) return null;
if (l1 != null && l2 == null) return l1;
if (l1 == null && l2 != null) return l2;
// 自定义头结点,最后只需返回自定义头结点的next即可
const prehead = new ListNode(-1);
let prev = prehead; // 记录已排序的链表的尾指针,方便指向下一个排序节点
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
prev.next = l1;
l1 = l1.next;
} else {
prev.next = l2;
l2 = l2.next;
}
prev = prev.next; // 更新prev,指向最新的尾部node
}
prev.next = l1 === null ? l2 : l1; // 最后把剩余的有序链表直接合并进来
return prehead.next; // 返回自定义头结点的next
}
// 递归
var mergeTwoLists = function (l1, l2) {
if (l1 === null) return l2;
if (l2 === null) return l1;
if (l1.val < l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 合并 K 个升序链表
- 递归或循环的方式两两合并即可
var mergeKLists = function (lists) {
if (lists.length === 0) return null;
return mergeArr(lists);
};
function mergeArr(lists) {
if (lists.length <= 1) return lists[0];
let index = Math.floor(lists.length / 2);
const left = mergeArr(lists.slice(0, index));
const right = mergeArr(lists.slice(index));
return merge(left, right);
}
function merge(l1, l2) {
if (l1 == null && l2 == null) return null;
if (l1 != null && l2 == null) return l1;
if (l1 == null && l2 != null) return l2;
let newHead = null,
head = null;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
if (!head) {
newHead = l1;
head = l1;
} else {
newHead.next = l1;
newHead = newHead.next;
}
l1 = l1.next;
} else {
if (!head) {
newHead = l2;
head = l2;
} else {
newHead.next = l2;
newHead = newHead.next;
}
l2 = l2.next;
}
}
newHead.next = l1 ? l1 : l2;
return head;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 25. K 个一组翻转链表
var reverseKGroup = function (head, k) {
if (!head || !head.next) return head;
let a = head,
b = head;
for (let i = 0; i < k; i++) {
if (b == null) return head;
b = b.next;
}
// 每次翻转a到b这一段
const newHead = reverse(a, b);
// 递归,a指向下一段新的head节点
a.next = reverseKGroup(b, k);
return newHead;
};
// 翻转a->b
function reverse(a, b) {
let prev = null,
cur = a,
nxt = a;
while (cur != b) {
nxt = cur.next;
cur.next = prev;
prev = cur;
cur = nxt;
}
return prev;
}
// 2.
var reverseKGroup = function (head, k) {
if (!head || !head.next) return head;
const dummy = new ListNode(-1, head);
let p0 = dummy;
let cur = head;
let len = 0;
while (cur) {
len++;
cur = cur.next;
}
while (len >= k) {
len -= k;
let pre = null;
cur = p0.next;
for (let i = 0; i < k; i++) {
const next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
const nxt = p0.next;
p0.next.next = cur;
p0.next = pre;
p0 = nxt;
}
return dummy.next;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 141. 环形链表
- 快慢指针判断链表有没有环,有环的话两个指针肯定会相遇(套圈),无环的话会退出。
var hasCycle = function (head) {
if (head == null || head.next == null) return false;
let slower = head,
faster = head;
while (faster != null && faster.next != null) {
slower = slower.next;
faster = faster.next.next;
if (slower === faster) return true;
}
return false;
};
2
3
4
5
6
7
8
9
10
11
# 142. 环形链表 2
如果有环,则返回环的入口节点。如果没有则返回 null。
- 快慢指针判断链表有没有环,有环的话两个指针肯定会相遇(套圈),无环的话会退出。
- 当快慢指针相遇时,将快指针重新指向头节点,然后快慢指针每次移动一步,当再次相遇时,就是环的入口节点。(数学计算出来的)
var detectCycle = function (head) {
if (!head || !head.next) return null;
let fast = head;
let slow = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
if (fast === slow) {
while (slow !== head) {
slow = slow.next;
head = head.next;
}
return slow;
}
}
return null;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 143. 重排链表
function findCenter(head) {
let slower = head,
faster = head;
while (faster && faster.next) {
slower = slower.next;
faster = faster.next.next;
}
return slower;
}
function reverse(head) {
let prev = null,
cur = head,
while (cur != null) {
let nxt = cur.next;
cur.next = prev;
prev = cur;
cur = nxt;
}
return prev;
}
function reorderList(head) {
if (!head || !head.next) return head;
let mid = findCenter(head);
let head2 = reverse(mid);
while (head2.next) {
let nxt = head.next;
let nxt2 = head2.next;
head.next = head2;
head2.next = nxt;
head = nxt;
head2 = nxt2;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 排序链表
- TODO
var sortList = function (head) {
if (head == null) return null;
let newHead = head;
return mergeSort(head);
};
function mergeSort(head) {
if (head.next != null) {
let slower = getCenter(head);
let nxt = slower.next;
slower.next = null;
console.log(head, slower, nxt);
const left = mergeSort(head);
const right = mergeSort(nxt);
head = merge(left, right);
}
return head;
}
function merge(left, right) {
let newHead = null,
head = null;
while (left != null && right != null) {
if (left.val < right.val) {
if (!head) {
newHead = left;
head = left;
} else {
newHead.next = left;
newHead = newHead.next;
}
left = left.next;
} else {
if (!head) {
newHead = right;
head = right;
} else {
newHead.next = right;
newHead = newHead.next;
}
right = right.next;
}
}
newHead.next = left ? left : right;
return head;
}
function getCenter(head) {
let slower = head,
faster = head.next;
while (faster && faster.next) {
slower = slower.next;
faster = faster.next.next;
}
return slower;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 相交链表
- TODO
var getIntersectionNode = function (headA, headB) {
let lastHeadA = null;
let lastHeadB = null;
let originHeadA = headA;
let originHeadB = headB;
if (!headA || !headB) {
return null;
}
while (true) {
if (headB == headA) {
return headB;
}
if (headA && headA.next == null) {
lastHeadA = headA;
headA = originHeadB;
} else {
headA = headA.next;
}
if (headB && headB.next == null) {
lastHeadB = headB;
headB = originHeadA;
} else {
headB = headB.next;
}
if (lastHeadA && lastHeadB && lastHeadA != lastHeadB) {
return null;
}
}
return null;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 98. 验证二叉搜索树
二叉搜索树的定义:左子节点小于父节点,右子节点大于父节点。
可以根据深度优先遍历的三种方式:前中后序遍历来验证:
- 前序遍历:根节点,左子树,右子树;先判断再递归,
- 中序遍历:左子树,根节点,右子树;中序遍历是递增序列,所以可以判断当前节点是不是大于上一个节点
- 后序遍历:左子树,右子树,根节点;先递归再判断,把边界带上去
// 后续
var isValidBST = function (root) {
function dfs(node) {
if (node == null) {
return [Infinity, -Infinity];
}
const [lMin, lMax] = dfs(node.left);
const [rMin, rMax] = dfs(node.right);
const x = node.val;
// 也可以在递归完左子树之后立刻判断,如果发现不是二叉搜索树,就不用递归右子树了
if (x <= lMax || x >= rMin) {
return [-Infinity, Infinity];
}
return [Math.min(lMin, x), Math.max(rMax, x)];
}
return dfs(root)[1] !== Infinity;
};
// 中序
var isValidBST = function (root) {
if (!root) return true;
let pre = -Infinity;
function dfs(node) {
if (!node) return true;
if (!dfs(node.left) || node.val <= pre) return false;
pre = node.val;
return dfs(node.right);
}
return dfs(root);
};
// 前序
var isValidBST = function (root, left = -Infinity, right = Infinity) {
if (!root) return true;
const val = root.val;
return left < val && val < right && isValidBST(root.left, left, val) && isValidBST(root.right, val, right);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 235. 二叉搜索树的最近公共祖先
# 236. 二叉树的最近公共祖先
# 寻找 2 个升序数组的中位数
- 暴力求解,先合并再计算中位数
- 双指针,都从头开始比较,谁小就向右移动谁的指针,直到第(m+n)/2 次
- 二分查找
- 类似求第 K 小的值的算法
// 二分 O(log(min(m,n)))
var findMedianSortedArrays = function (nums1, nums2) {
// nums1长度比nums2小
if (nums1.length > nums2.length) {
[nums1, nums2] = [nums2, nums1];
}
let m = nums1.length;
let n = nums2.length;
// 在0~m中查找
let left = 0;
let right = m;
// median1:前一部分的最大值
// median2:后一部分的最小值
let median1 = 0;
let median2 = 0;
while (left <= right) {
// 前一部分包含 nums1[0 .. i-1] 和 nums2[0 .. j-1]
// 后一部分包含 nums1[i .. m-1] 和 nums2[j .. n-1]
const i = left + Math.floor((right - left) / 2);
const j = Math.floor((m + n + 1) / 2) - i;
const maxLeft1 = i === 0 ? -Infinity : nums1[i - 1];
const minRight1 = i === m ? Infinity : nums1[i];
const maxLeft2 = j === 0 ? -Infinity : nums2[j - 1];
const minRight2 = j === n ? Infinity : nums2[j];
if (maxLeft1 <= minRight2) {
median1 = Math.max(maxLeft1, maxLeft2);
median2 = Math.min(minRight1, minRight2);
left = i + 1;
} else {
right = i - 1;
}
}
return (m + n) % 2 == 0 ? (median1 + median2) / 2 : median1;
};
// 双指针 O(m+n)
var findMedianSortedArrays = function (nums1, nums2) {
let n1 = nums1.length;
let n2 = nums2.length;
// 两个数组总长度
let len = n1 + n2;
// 保存当前移动的指针的值(在nums1或nums2移动),和上一个值
let preValue = -1;
let curValue = -1;
// 两个指针分别在nums1和nums2上移动
let point1 = 0;
let point2 = 0;
// 需要遍历len/2次,当len是奇数时,最后取curValue的值,是偶数时,最后取(preValue + curValue)/2的值
for (let i = 0; i <= Math.floor(len / 2); i++) {
preValue = curValue;
// 需要在nums1上移动point1指针
if (point1 < n1 && (point2 >= n2 || nums1[point1] < nums2[point2])) {
curValue = nums1[point1];
point1++;
} else {
curValue = nums2[point2];
point2++;
}
}
return len % 2 === 0 ? (preValue + curValue) / 2 : curValue;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 寻找关联子串的位置
给定两个字符串 str1 和 str2,如果字符串 str1 中的字符,经过排列组合后的字符串中,只要有一个字符串是 str2 的子串,则认为 str1 是 str2 的关联子串。
若 str1 是 str2 的关联子串,请返回子串在 str2 的起始位置;若 str2 中有多个 str1 的组合子串,请返回最小的起始位置。若不是关联子串,则返回-1。
function findSubstring(s1, s2) {
const l1 = s1.length;
const l2 = s2.length;
let result = -1;
const target = s1.split("").sort().join("");
for (let i = 0; i < l2 - l1; i++) {
const s = s2.substring(i, i + l1);
const t = s.split("").sort().join("");
if (target === t) {
result = i;
break;
}
}
console.log(result);
}
const testList = [
{ str1: "abc", str2: "efghicabiii" },
{ str1: "abc", str2: "efghicaibii" },
];
testList.forEach((v) => {
const { str1, str2 } = v;
findSubstring(str1, str2);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 深度优先遍历 DOM 节点
- el.childNodes:获取全部节点,包括 element 节点、注释节点、文本节点等等,返回的是:NodeList[]
- el.children:只获取 element 节点,不获取注释节点、文本节点,返回的是:HTMLCollection[]
// 递归
function dfs1(root) {
visitNode(root);
const childNodes = root.childNodes; // childNodes与children不同!
if (childNodes.length) {
childNodes.forEach((child) => {
dfs1(child); // 递归
});
}
}
// 不用递归,用栈
function dfs2(root) {
const stack = [];
// 根节点入栈
stack.push(root);
while (stack.length) {
const curNode = stack.pop();
if (!curNode) break;
visitNode(curNode);
// 子节点压栈
const childNodes = curNode.childNodes;
if (childNodes.length) {
// reverse反顺序压栈
Array.from(childNodes)
.reverse()
.forEach((child) => stack.push(child));
}
}
}
function visitNode(node) {
if (node instanceof Comment) {
// 注释节点
console.log("Comment node ---", node.textContent);
}
if (node instanceof Text) {
// 文本节点
const t = node.textContent?.trim();
if (t) {
console.log("Text node ---", t);
}
}
if (node instanceof HTMLElement) {
// element节点
console.log("HTMLElement node ---", `<${node.tagName.toLowerCase()}>`);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 广度优先遍历 DOM 节点
function bfs(root) {
const queue = [];
// 根节点入队
queue.unshift(root);
while (queue.length) {
const curNode = queue.pop();
visitNode(curNode); // 工具函数,判断节点类型然后做需要的处理
// 子节点入队
const childNodes = curNode.childNodes;
if (childNodes.length) {
childNodes.forEach((child) => queue.unshift(child));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 手写柯里函数
function curry(fn) {
const fnArgsLength = fn.length;
let args = [];
function calc(...newArgs) {
args = [...args, ...newArgs];
if (args.length < fnArgsLength) {
return calc;
} else {
return fn.apply(this, args.slice(0, fnArgsLength));
}
}
return calc;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 手写 call 函数
function customCall(ctx, ...args) {
if (ctx == null) {
ctx = globalThis;
}
// 值类型返回一个包装类
if (typeof ctx !== "object") {
ctx = new Object(ctx);
}
// 防止属性名覆盖
const fnKey = Symbol();
// this就是当前的函数
ctx[fnKey] = this;
const res = ctx[fnKey](...args);
// 清理掉fn,防止污染
delete ctx[fnKey];
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 手写 apply 函数
function customApply(ctx, args) {
if (ctx == null) {
ctx = globalThis;
}
// 值类型返回一个包装类
if (typeof ctx !== "object") {
ctx = new Object(ctx);
}
const fnKey = Symbol();
ctx[fnKey] = this;
const res = ctx[fnKey](...args);
delete ctx[fnKey];
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 手写 EventBus 函数
/*
this.events:存放各种类型对应的全部事件函数,格式:{key1:[{fn:fn1, isOnce: false},{fn:fn2, isOnce: true}],key2:[],...}
*/
class EventBus {
constructor() {
this.events = {};
}
on(type, fn, isOnce = false) {
const events = this.events;
if (events[type] == null) {
events[type] = [];
}
events[type].push({ fn, isOnce });
}
once(type, fn) {
this.on(type, fn, true);
}
off(type, fn) {
if (!fn) {
this.events = [type];
} else {
const fnList = this.events[type];
if (fnList) {
this.events[type] = fnList.filter((item) => item.fn !== fn);
}
}
}
emit(type, ...args) {
const fnList = this.events[type];
if (!fnList) return;
// 注意,使用filter,实现遍历执行并且把once的执行后移除
this.events[type] = fnList.filter((item) => {
const { fn, isOnce } = item;
fn(...args);
return isOnce ? false : true;
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 手写 LRU 缓存函数
使用 Map 实现,Map 中的存储是有序的,且取值赋值速度都比数组链表栈等快的多,Map 也有 size 属性。
class LRUCache {
length = undefined;
data = new Map();
constructor(length) {
if (!length) throw new Error("Invalid length!");
this.length = length;
}
set(key, value) {
const data = this.data;
if (data.has(key)) data.delete(key);
data.set(key, value);
if (data.size > this.length) {
const deleteKey = data.keys().next().value;
data.delete(deleteKey);
}
}
get(key) {
const data = this.data;
if (!data.has(key)) return null;
const val = data.get(key);
data.delete(key);
data.set(key, val);
return val;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 扁平数组转成树
function convert2Tree(arr) {
const idToTreeNode = new Map();
let root = null;
arr.forEach((item) => {
const { id, name, parentId } = item;
const treeNode = { id, name };
idToTreeNode.set(id, treeNode);
const parentNode = idToTreeNode.get(parentId);
if (parentNode) {
if (parentNode.children == null) {
parentNode.children = [];
}
parentNode.children.push(treeNode);
}
if (parentId === 0) root = treeNode;
});
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 树转成扁平数组
function convert2Array(root) {
const arr = [];
// 用来存 子节点和父节点的映射关系
const nodeToParent = new Map();
// 广度优先用队列先进先出 unshift+pop
const queue = [];
queue.unshift(root);
while (queue.length) {
const curNode = queue.pop();
if (curNode == null) break;
const { id, name, children = [] } = curNode;
const parentNode = nodeToParent.get(curNode);
const parentId = parentNode?.id || 0;
const item = { id, name, parentId };
arr.push(item);
children.forEach((node) => {
nodeToParent.set(node, curNode);
queue.unshift(node);
});
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 手写 LazyMan 函数,实现 sleep 功能
class LazyMan {
constructor(name) {
this.name = name;
this.tasks = [];
setTimeout(() => {
this.next();
}, 0);
}
next() {
const task = this.tasks.shift();
if (task) task();
}
sleep(delay) {
this.tasks.push(() => {
setTimeout(() => {
this.next();
}, delay * 1000);
});
return this;
}
eat(food) {
this.tasks.push(() => {
console.log(`eat ${food}`);
this.next();
});
return this;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 求数组某个范围上的最大值
- 遍历,记录最大值并返回
- 递归,一分为二,找每个区间上的最大值,最后返回最大的那个,实例:
function process(arr, l, r) {
if (l === r) return arr[l]; // 只有一个数时直接返回
let mid = l + ((r - l) >> 1); // 位运算比除法快
let lMax = process(arr, l, mid);
let rMax = process(arr, mid + 1, r);
return Math.max(lMax, rMax);
}
function getMax(arr) {
return process(arr, 0, arr.length - 1);
}
2
3
4
5
6
7
8
9
10
# 山月前端工程化
厘清几个概念
# Babel、SWC
- Babel 是广泛使用的 JavaScript 编译器,用于把 ES6+代码转换为 ES5 代码,使之可以兼容低端浏览器和 node 环境;
- swc 是使用 Rust 编写的高性能 TypeScript / JavaScript 转译器,类似于 Babel,有至少 10 倍以上的性能优势,也是用来将 ES6+ 转化为 ES5 ;
- swc 和 babel 命令可以相互替换,并且大部分的 babel 插件也已经实现。
- swc 与 babel 一样,将命令行工具、编译核心模块分化为两个包。
@swc/cli类似于@babel/cli;@swc/core类似于@babel/core;
# core-js、polyfill
- core-js 是关于 ES 标准最出名的 polyfill 库,是实现 JavaScript 标准运行库之一,它提供了从 ES3 ~ ES7+ 以及还处在提案阶段的 JavaScript 的实现。
- polyfill 意指当浏览器不支持某一最新 API 时,它将帮你实现,中文叫做垫片。
- core-js 包含了所有 ES6+ 的 polyfill,并集成在 babel/swc 等编译工具之中。
- @babel/plugin-transform-runtime - 重利用 Babel helper 方法的 babel 插件,避免全局补丁污染
- @babel/polyfill - 等同于
core-js/stable和regenerator-runtime/runtime,已废弃 - @babel/preset-env - 按需编译和按需打补丁
# @babel/preset-env、@babel/polyfill
- 使用
@babel/preset-env(推荐) 或者@babel/polyfill(废弃) 进行配置 core-js,以实现 polyfill。
rules: [
{
test: /\.js$/,
use: {
loader: "babel-loader",
options: {
presets: [
// 使用数组
[
"@babel/preset-env",
{
// 数组的第二项为env选项 示例
// 指定市场份额超过0.25%的浏览器(不推荐,会导致对IE6的支持)
// targets:指定目标环境(String | Object | Array),不指定时会根据browserlist配置(.browserlistrc或package.json)去兼容目标环境
targets:"> 0.25%, not dead",
// 推荐写法:兼容所有浏览器最后两个版本
targets:"last 2 versions"
// 对象写法
targets:{
// 指定浏览器版本
"chrome": "58",
"ie":"11",
"edge":"last 2 versions",
"firefox":"> 5%",
// 指定nodejs版本, current为当前运行的node版本
"node":"current"
},
// spec : 启用更符合规范的转换,但速度会更慢,默认为 false
// loose:是否启动松散模式(默认:false),
// modules:将 ES Modules 转换为其他模块规范,adm | umd | systemjs | commonjs | cjs | false(默认)
// debug:是否启用debug模式,默认 false
// useBuiltIns:配置@babel/preset-env如何处理polyfills,有三个值:
// 1. entry:根据配置的浏览器兼容,引入浏览器不兼容的 polyfill。需要在入口文件手动添加 import '@babel/polyfill',会自动根据 browserslist 替换成浏览器不兼容的所有 polyfill
// 2. usage:会根据配置的浏览器兼容,以及你代码中用到的 API 来进行 polyfill,实现了按需添加,好处就是最终打包的文件会比较小
// 3. false(默认):此时不对 polyfill 做操作。如果引入 @babel/polyfill,则无视配置的浏览器兼容,引入所有的 polyfill
// corejs:指定corejs版本(默认:2.0),目前使用core-js@2或core-js@3版本,需要手动安装
},
],
],
},
},
},
];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# @babel/preset-react、@babel/preset-typescript
# browserslist 的意义
- browserslist (opens new window)用特定的语句来查询浏览器列表,如
last 2 Chrome versions。package.json 中也有类似语句。 - 它是现代前端工程化不可或缺的工具,无论是处理 JS 的 babel,还是处理 CSS 的 postcss,凡是与垫片相关的,他们背后都有 browserslist 的身影。
- babel,在 @babel/preset-env 中使用 core-js 作为垫片
- postcss 使用 autoprefixer 作为垫片
- 前端打包体积与垫片的关系:
- 由于低浏览器版本的存在,垫片是必不可少的
- 垫片越少,则打包体积越小
- 浏览器版本越新,则垫片越少
- 原理: browserslist 根据正则解析查询语句,对浏览器版本数据库 caniuse-lite 进行查询,返回所得的浏览器版本列表。
- 使用以下命令手动更新 caniuse-lite 数据库:
npx browserslist@latest --update-db。
# 浏览器中如何使用原生的 ESM
- Native Import: Import from URL--通过
script[type=module],可直接在浏览器中使用原生 ESM。这也使得前端不打包 (Bundless) 成为可能(Vite)。
<script type="module">
import lodash from "https://cdn.skypack.dev/lodash";
</script>
2
3
- 由于前端跑在浏览器中,因此它也只能从 URL 中引入 Package
// 由于 http import 的引入,可以直接在浏览器控制台引入第三方package
lodash = await import("https://cdn.skypack.dev/lodash");
lodash.get({ a: 3 }, "a");
2
3
4
- ImportMap:在 ESM 中,可通过 importmap 使得裸导入可正常工作:
<script type="importmap">
{
"imports": {
"lodash": "https://cdn.skypack.dev/lodash",
"ms": "https://cdn.skypack.dev/ms"
}
}
</script>
2
3
4
5
6
7
8
- Import Assertion: 通过
script[type=module],不仅可引入 Javascript 资源,甚至可以引入 JSON/CSS,示例如下:
<script type="module">
import data from "./data.json" assert { type: "json" };
console.log(data);
</script>
2
3
4
5
# JavaScript 的模块化
为什么会有多种种模块化规范,JavaScript 官方迟迟没有给出解法,所以社区实现了很多不同的模块化规范,按照出现的时间前后有 CommonJS、AMD、CMD、UMD。最后才是 JavaScript 官方在 ES6 提出的 ES Module。众所周知,早期的 JavaScript 是没有模块的概念,引用第三方包时都是把变量直接绑定在全局环境下。以 axios 为例,以 script 标签引入 axios 时,实际是在 window 对象上绑定了一个 axios 属性。这种全局引入的方式会导致两个问题,变量污染和依赖混乱。所以需要使用“模块化”来对不同代码进行「隔离」。
- 变量污染:所有脚本都在全局上下文中绑定变量,如果出现重名时,后面的变量就会覆盖前面的
- 依赖混乱:当多个脚本有相互依赖时,彼此之间的关系不明朗
# ESModule 与 CommonJS 的导入导出的不同
在 ESM 中,导入导出有两种方式:
- 具名导出/导入: Named Import/Export
- 默认导出/导入: Default Import/Export
- ES6 模块化不是对象,import 会在 JavaScript 引擎静态分析,在编译时就引入模块代码,而并非在代码运行时加载,因此也不适合异步加载。
CommonJS 中,导入导出的方法只有一种:
module.exports = xxx;- 而所谓的 exports 仅仅是
module.exports的引用而已:exports = module.exports; - 多个
module.exports.xxx导出的值会合并成一个对象 module.exports导出的值为默认值,会忽略module.exports.xxx导出的值- CommonJS 一般用在服务端或者 Node 用来同步加载模块,它对于模块的依赖发生在代码运行阶段,不适合在浏览器端做异步加载。
exports 的转化:cjs==>ESM:
- 当 exports 转化时,既要转化为具名导出
export {},又要转化为默认导出export default {}
- 当 exports 转化时,既要转化为具名导出
module.exports 的转化:cjs==>ESM:
- 我们可以遍历其中的 key (通过 AST),将 key 转化为具名导出
Named Export,将 module.exports 转化为默认导出Default Export
- 我们可以遍历其中的 key (通过 AST),将 key 转化为具名导出
ESModule 的优势:
- 死代码检测和排除。我们可以用静态分析工具检测出哪些模块没有被调用过。未被调用到的模块代码永远不会被执行,也就成为了死代码。通过静态分析可以在打包时去掉这些未曾使用过的模块,以减小打包资源体积。
- 模块变量类型检查。JavaScript 属于动态类型语言,不会在代码执行前检查类型错误。ES6 Module 的静态模块结构有助于确保模块之间传递的值或接口类型是正确的。
- 编译器优化。在 CommonJS 等动态模块系统中,无论采用哪种方式,本质上导入的都是一个对象,而 ES6 Module 支持直接导入变量,减少了引用层级,程序效率更高。
二者的差异:
- CommonJS 模块引用后是一个值的拷贝,简单来说就是把导出值复制一份,放到一块新的内存中,每次直接在新的内存中取值,所以对变量修改没有办法同步。
- ESModule 引用后是一个值的动态映射,指向同一块内存,并且这个映射是只读的。
- CommonJS 模块输出的是值的拷贝,一旦输出之后,无论模块内部怎么变化,都无法影响之前的引用。
- ESModule 是引擎会在遇到 import 后生成一个引用链接,在脚本真正执行时才会根据这个引用链接去模块里面取值,模块内部的原始值变了 import 加载的模块也会变。模块实际导出的是这块内存的地址,每当用到时根据地址找到对应的内存空间,这样就实现了所谓的“动态绑定”。
- CommonJS 运行时加载。
- ESModule 编译阶段引用。
- CommonJS 在引入时是加载整个模块,生成一个对象,然后再从这个生成的对象上读取方法和属性。
- ESModule 不是对象,而是通过 export 暴露出要输出的代码块,在 import 时使用静态命令的方法引用指定的输出代码块,并在 import 语句处执行这个要输出的代码,而不是直接加载整个模块。
CommonJS To ESM 的构建工具:
@rollup/plugin-commonjs,https://cdn.skypack.dev/,https://jspm.org/。
# ESModule 导入导出
- 普通导入、导出:使用 export 导出可以写成一个对象合集,也可以是一个单独的变量,需要和 import 导入的变量名字一一对应;
- 默认导入、导出:使用
export default语法可以实现默认导出,可以是一个函数、一个对象,或者仅一个常量。默认的意思是,使用 import 导入时可以使用任意名称; - 混合导入、导出:默认导入导出不会影响普通导入导出,并且可以同时使用;
- 全部导入:使用'*'、'as'等关键字;实际可以理解为:默认导出的属性名就叫'default',只不过省略了。
- 重命名导入:可以避免命名冲突;
- 重定向导出:很有用;
export * from "./a.mjs"; // 第一种
export { propA, propB, propC } from "./a.mjs"; // 第二种
export { propA as renameA, propB as renameB, propC as renameC } from "./a.mjs"; //第三种
2
3
- 只运行模块:
import './a.mjs',相当于直接运行这个文件里的代码。
# ESModule 循环引入
import 语句有提升的效果。
ES module 会根据 import 关系构建一棵依赖树,遍历到树的叶子模块后,然后根据依赖关系,反向找到父模块,将 export/import 指向同一地址。
和 CommonJS 一样,发生循环引用时并不会导致死循环,但两者的处理方式大有不同。
ES module 导出的是一个索引——内存地址,没有办法和 CommonJS 一样通过缓存处理。它依赖的是模块地图和模块记录,模块地图在下面会解释,而模块记录是好比每个模块的“身份证”,记录着一些关键信息——这个模块导出值的的内存地址,加载状态,在其他模块导入时,会做一个“连接”——根据模块记录,把导入的变量指向同一块内存,这样就是实现了动态绑定。
在代码执行前,首先要进行预处理,这一步会根据 import 和 export 来构建模块地图(Module Map),它类似于一颗树,树中的每一个'节点'就是一个模块记录,这个记录上会标注导出变量的内存地址,将导入的变量和导出的变量连接,即把他们指向同一块内存地址。不过此时这些内存都是空的,也就是看到的'uninitialized'。
循环引用要解决的无非是两个问题,保证不进入死循环以及输出什么值。ES Module 处理循环使用一张模块间的依赖地图来解决死循环/循环引用问题,标记进入过的模块为'获取中 Fetching',所以循环引用时不会再次进入;使用模块记录,标注要去哪块内存中取值,将导入导出做链接,解决了要输出什么值。
# CommonJS 中 exports 和 module.exports 的区别
- 所谓的 exports 仅仅是
module.exports的引用而已:exports = module.exports;,但是使用的时候还是有些区别; - 当绑定一个属性时,两者相同
exports.propA = "A";
module.exports.propB = "B";
2
- 不能直接赋值给
exports,也就是不能直接使用exports = {};这种语法
// 失败
exports = { propA: "A" };
// 成功
module.exports = { propB: "B" };
2
3
4
- 虽然两者指向同一块内存,但最后被导出的是
module.exports,所以不能直接赋值给 exports。同样的道理,只要最后直接给module.exports赋值了,之前绑定的属性都会被覆盖掉。
exports.propA = "A";
module.exports.propB = "B";
module.exports = { propD: "D" };
module.exports = { propC: "C" }; // propC会覆盖propD
2
3
4
用上面的例子所示,先是绑定了两个属性 propA 和 propB,接着给 module.exports 赋值,最后能成功导出的只有 propC。
# CommonJS 如何处理循环引入和多次引入
- 循环引入
先看示例:执行node index.js,会输出什么:
//index.js
var a = require("./a");
console.log("入口模块引用a模块:", a);
// a.js
exports.a = "原始值-a模块内变量";
var b = require("./b");
console.log("a模块引用b模块:", b);
exports.a = "修改值-a模块内变量";
// b.js
exports.b = "原始值-b模块内变量";
var a = require("./a");
console.log("b模块引用a模块:", a);
exports.b = "修改值-b模块内变量";
// 输出
// b模块引用a模块:{a: '原始值-a模块内变量'}
// a模块引用b模块:{b: '修改值-b模块内变量'}
// 入口模块引用a模块:{a: '修改值-a模块内变量'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这种 AB 模块间的互相引用,本应是个死循环,但是实际并没有,因为 CommonJS 做了特殊处理——模块缓存。
循环引用无非是要解决两个问题,怎么避免死循环以及输出的值是什么。CommonJS 通过模块缓存来解决:每一个模块都先加入缓存再执行,每次遇到 require 都先检查缓存,这样就不会出现死循环;借助缓存,输出的值也很简单就能找到了。
- 多次引入
同样由于缓存,一个模块不会被多次执行。当第二次引用这个模块时,如果发现已经有缓存,则直接读取,而不会再去执行一次。
- 路径解析规则
为什么我们导入时直接简单写一个'react'就正确找到包的位置?每个模块都是一个 module 对象,module 下面有 paths 属性。
首先把路径作一个简单分类:内置的核心模块、本地的文件模块和第三方模块。
- 对于核心模块,node 将其已经编译成二进制代码,直接书写标识符 fs、http 就可以引入使用;
- 对于自己写的文件模块,需要用'./'、'../'开头,require 会将这种相对路径转化为真实路径,找到模块;
- 对于第三方模块,也就是使用 npm 下载的包,就会用到 paths 这个变量,会依次查找当前路径下的 node_modules 文件夹,如果没有,则在父级目录查找 node_modules,一直到根目录下,找到为止。如果没找到那就会报模块没找到或没安装。
在 node_modules 下找到对应包后,会以 package.json 文件下的 main 字段为准,找到包的入口,如果没有 main 字段,则查找 index.js/index.json/index.node 做入口。
# export 和 export default 的区别
| 特性 | export | export default |
|---|---|---|
| 导出数量 | 可以导出多个命名导出 | 只能有一个默认导出 |
| 导入方式 | 必须使用 {} 括起来指定导入内容,也可以使用*全部导入并设置一个统一模块名称 | 可以直接导入或者指定别名,无需 {} |
| 导入时的命名 | 导入名称必须与导出名称一致 | 可以自定义导入名称 |
| 使用场景 | 用于多个功能、变量、类的导出 | 用于模块的数的导出 |
import * as Utils from './utils.js';可以创建了一个包含 utils.js 中所有命名导出的对象 Utils。然后使用Utils.xxx来调用具体的方法属性即可。import * as XX不能与export default一起使用:如果 utils.js 中有默认导出(export default),使用import * as时,默认导出不会包含在 Utils 对象中。你仍需单独导入默认导出。- 确保在同一作用域中没有命名冲突。如果模块中有多个导出项,确保它们具有唯一的名称或使用别名避免冲突。
- 在一个模块中,可以同时使用 export 和 export default
# const、let 和 var
- 在 ES5 中,顶层对象的属性和全局变量是等价的,var 命令和 function 命令声明的全局变量,自然也是顶层对象。
- 但 ES6 规定,var 命令和 function 命令声明的全局变量,依旧是顶层对象的属性,但 let 命令、const 命令、class 命令声明的全局变量,不属于顶层对象的属性。
- 在定义变量的块级作用域中就能获取到 let、const 声明的对象,既然不属于顶层对象,那就不需要加 window(global)。
- var 的话会直接在栈内存里预分配内存空间,然后等到实际语句执行的时候,再存储对应的变量,如果传的是引用类型,那么会在堆内存里开辟一个内存空间存储实际内容,栈内存会存储一个指向堆内存的指针。
- let 的话,是不会在栈内存里预分配内存空间,而且在栈内存分配变量时,做一个检查,如果已经有相同变量名存在就会报错。
- const 的话,也不会预分配内存空间,在栈内存分配变量时也会做同样的检查。不过 const 存储的变量是不可修改的,对于基本类型来说你无法修改定义的值,对于引用类型来说你无法修改栈内存里分配的指针,但是你可以修改指针指向的对象里面的属性。
- let、const 只是创建过程提升,初始化过程并没有提升,所以会产生暂时性死区。var 的创建和初始化过程都提升了,所以在赋值前访问会得到 undefined。function 的创建、初始化、赋值都被提升了。
# SEO
- SEO(Search Engine Optimization),即搜索引擎优化。SEO 是随着搜索引擎的出现而来的,两者是相互促进,互利共生的关系。SEO 的存在就是为了提升网页在搜索引擎自然搜索结果中的收录数量以及排序位置而做的优化行为。而优化的目的就是为了提升网站在搜索引擎中的权重,增加对搜索引擎的友好度,使得用户在访问网站时能排在前面。
- 分类:白帽 SEO 和黑帽 SEO。白帽 SEO,起到了改良和规范网站设计的作用,使网站对搜索引擎和用户更加友好,并且网站也能从搜索引擎中获取合理的流量,这是搜索引擎鼓励和支持的。黑帽 SEO,利用和放大搜索引擎政策缺陷来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持与鼓励的。
- 目的:提高网站的权重,增强搜索引擎友好度,以达到提高网站排名,增加流量曝光,改善(潜在)用户体验,促进销售的作用。
- 具体方向:
- 对网站的标题、关键字、描述精心设置,反映网站的定位,让搜索引擎明白网站是做什么的;
- 网站内容优化:内容与关键字的对应,增加关键字的密度;
- 在网站上合理设置 Robots.txt 文件;robots.txt 文件规定了搜索引擎抓取工具可以访问你网站上的哪些网址, 此文件主要用于避免网站收到过多请求。可以存放 sitemap.xml 的链接
- 生成针对搜索引擎友好的网站地图 sitemap.xml;
- 增加外部链接,到各个网站上宣传。
- 前端 SEO
网站结构布局优化:尽量简单、开门见山,提倡扁平化结构
- 控制首页链接数量:网站首页是权重最高的地方;链接不能太多也不能太少,要有实质性的链接;
- 扁平化的目录层次:不超过 3 层;
- 导航优化:尽量采用文字,图片标签必须添加“alt”和“title”属性;在每一个网页上应该加上面包屑导航;
- 网站的结构布局:主次关系清晰;
- 利用布局,把重要内容 HTML 代码放在最前
- 控制页面的大小,减少 http 请求,提高网站的加载速度
网页代码优化
- ssr:服务端渲染返回给客户端的是已经获取了异步数据并执行 JavaScript 脚本的最终 HTML,网络爬虫可以抓取到完整的页面信息,SSR 另一个很大的作用是加速首屏渲染;
- 突出重要内容---合理的设计全局 title、description 和 keywords:把重要的关键词放在前面,关键词不要重复出现,切记不能太长,过分堆砌关键词,每个页面也要有所不同-每个页面自定义 TDK;
- 语义化书写 HTML 代码,符合 W3C 标准
- 标签:页内链接,要加 title 属性加以说明,让访客和爬虫知道。而外部链接,链接到其他网站的,则需要加上
rel="nofollow"属性, 告诉爬虫不要爬,因为一旦爬虫爬了外部链接之后,就不会再回来了,还可加上 noopener、noreferrer - 正文标题要用 h1,副标题用 h2,不可乱用 h 标签
- 图片应使用 "alt" 属性加以说明,设置宽高,减少重排重绘,提高加载速度
- 表格标题使用 caption 元素
- br 标签只用于文本内容换行
- 强调内容时使用 strong 标签
- 文本缩进不要使用特殊符号,应使用 css 进行设置
- 重要内容不要用 js 输出,须放在 html 里
- 尽量少使用 iframe
- 搜索引擎会过滤掉
display:none的元素中的内容 - 精简 url:URL 尽量短,长 URL 不仅不美观,用户还很难从中获取额外有用的信息。另一方面,短 url 还有助于减小页面体积,加快网页打开速度,提升用户体验。
- 多页文章:如果您的文章分为几个页面,请确保有可供用户点击的下一页和上一页链接,并且这些链接是可抓取的链接。
- 显示实用的 404 页面,使用自定义 404 页面能够有效引导用户返回到您网站上的正常网页,从而大幅提升用户的体验。
- 移动端设置 meta 标签:
<meta name='viewport' content='width=device-width, initial-scale=1'>,告知浏览器如何在移动设备上呈现网页 - Open Graph protocol:用来标注页面类型和描述页面内容,从而方便在社交媒体中进行传播。meta 标签的 name 都是以 og: 开头-
<meta name="og:title" property="og:title" content="xxx">,可以借助Front Matter自定义每个页面的 og 属性,也可以借助现有的插件 - JSON-LD:JavaScript Object Notation for Linked Data,用来描述网页的类型和内容,方便搜索引擎做展现。
<script type="application/ld+json">{JSON-LD}</script>,手写个插件,打包的时候往 index.html 的 head 里注入这段脚本即可。
站外优化
- 在搜素引擎排名较高的公众平台(百家号 ,知道,贴吧、搜狐、知乎等)发布正面网站信息,以建设良好口碑 ;负面信息排名较高的需删除或者屏蔽处理。
- 百度,互动,搜狗等百科的创建更新与维护,(互动百科在今日头条有着较高的排名,现在今日头条也在发展搜素引擎),百科对树立品牌形象较为重要。
- 公关舆情传播,宣传新闻源发布。
- 站外推广与外链建设。
- 百度收录添加站点、提交收录;谷歌收录添加站点、DNS 验证站点、提交收录、提交站点地图,在谷歌搜索栏使用 site:域名, 来确认站点是否已被谷歌收录;
- 360 收录、Bing 站长、搜狗站长、神马站长等操作同上
- 站长工具:百度统计、百度搜索资源平台、Google Analytics、Google Search Console、Google Search Central、Google Trending、站长工具、ahrefs、5118,可以对目标网站进行访问数据统计和分析,并提供多种参数供网站拥有者使用。
面向特定搜索引擎优化
- 多个域名 ip 统一成一个域名,并使用 https,Google 会优先选择 HTTPS 网页(而非等效的 HTTP 网页)作为规范网页。
- 有自己的服务器可以域名重定向或者 Nginx 重定向(http 重定向到 https,建议使用 301 永久重定向,SEO 友好),否则使用 js 重定向,手动判断并设置
location.href。 - 示例如下:注意 rewrite 这句,我们加了一个 permanent,表示这是一个 301 重定向,如果不加这个,会是 302 重定向,虽然表现上是一样的,但对于搜索引擎来说,却是不一样的,Google 也是更建议使用 301 重定向。重定向时要考虑 cookie 的同源策略,以免出现登录或者鉴权 bug。
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
rewrite ^(.*)$ https://$host$1 permanent;
# ...
}
2
3
4
5
6
7
- 重定向的处理
- 如果一个页面有两个地址,搜索引擎会认为它们是两个网站,结果造成每个搜索链接都减少导致网站排名降低,而如果使用 301 重定向,搜索引擎会把两个访问地址归到同一个网站排名下,不会影响 SEO。
- 用不同的地址会造成缓存友好性变差,当一个页面有好几个名字时,他可能会被缓存多次。
- 重定向时,如果路径指向同一台服务器,那么可以用 alias 和 mod_rewrite 配置跳转即可
- 重定向如果是因为域名发生变化,那么可以创建一条 CNAME(即创建一个指向另一个域名的 DNS 记录作为别名),结合 alias 或 mod_rewrite 配置跳转
- 测试与优化工具
- 使用站长工具
- 使用 Lighthouse
- web.dev
- Page Speed Insights
# 前端技术选型要考虑什么
# 协程
协程是一种比线程更加轻量级的存在,是语言层级的构造,可看作一种形式的控制流,在内存间执行,没有像线程间切换的开销。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程。
协程概念的提出比较早,单核 CPU 场景中发展出来的概念,通过提供挂起和恢复接口,实现在单个 CPU 上交叉处理多个任务的并发功能。
那么本质上就是在一个线程的基础上,增加了不同任务栈的切换,通过不同任务栈的挂起和恢复,线程中进行交替运行的代码片段,实现并发的功能。
总结一下 Generator 的本质,暂停,它会让程序执行到指定位置先暂停(yield),然后再启动(next),再暂停(yield),再启动(next),而这个暂停就很容易让它和异步操作产生联系,因为我们在处理异步时:开始异步处理(网络求情、IO 操作),然后暂停一下,等处理完了,再该干嘛干嘛。不过值得注意的是,js 是单线程的(又重复了三遍),异步还是异步,callback 还是 callback,不会因为 Generator 而有任何改变。
# js 中的 sort 函数
没有默认值函数时,是按照 UTF-16 排序的,对于字母数字 你可以利用 ASCII 进行记忆。(a-b)是从小到大排序。
# 非匿名自执行函数,函数名只读
# call 和 apply 的区别是什么,哪个性能更好一些
Function.prototype.apply 和 Function.prototype.call 的作用是一样的,区别在于传入参数的不同;
- 第一个参数都是,指定函数体内 this 的指向;
- 第二个参数开始不同,apply 是传入带下标的集合,数组或者类数组,apply 把它传给函数作为参数,call 从第二个开始传入的参数是不固定的,都会传给函数作为参数。
- call 比 apply 的性能要好,平常可以多用 call, call 传入参数的格式正是内部所需要的格式。
- 尤其是 es6 引入了 Spread operator (延展操作符) 后,即使参数是数组,也可以使用 call。
- 算法步骤中,apply 多了 CreateListFromArrayLike 的调用,其他的操作几乎是一样的(甚至 apply 仍然多了点操作)。
# 箭头函数与普通函数(function)的区别
- 箭头函数体内的 this 对象,就是定义时所在的对象,而不是使用时所在的对象。
- 不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
- 不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
- 不可以使用 new 命令,因为:
- 没有自己的 this,无法调用 call,apply。
- 没有 prototype 属性 ,而 new 命令在执行时需要将构造函数的 prototype 赋值给新的对象的
__proto__。 - 箭头函数并没有
[[Construct]]方法, 所以不能被用作构造函数。
# a.b.c.d 和 a['b']['c']['d'],哪个性能更高
- []是常量时,性能差别很小。dot 稍快;
- []是变量时,可能需要计算,性能略差;
- 从 AST 角度看就很简单了,
a['b']['c']和a.b.c,转换成 AST 前者的的树是含计算的,后者只是 string literal,天然前者会消耗更多的计算成本,时间也更长; - 后者 AST 会大一些,但在 AST 解析上消耗的这点时间基本可以忽略不计。
# ES6 代码转成 ES5 代码的实现思路
Babel 是如何把 ES6 转成 ES5 呢,其大致分为三步:
- 将代码字符串解析成抽象语法树,即所谓的 AST
- 对 AST 进行处理,在这个阶段可以对 ES6 代码进行相应转换,即转成 ES5 代码
- 根据处理后的 AST 再生成代码字符串
- 比如,可以使用 @babel/parser 的 parse 方法,将代码字符串解析成 AST;使用 @babel/core 的 transformFromAstSync 方法,对 AST 进行处理,将其转成 ES5 并生成相应的代码字符串;过程中,可能还需要使用 @babel/traverse 来获取依赖文件等。
- 补充说明
- .vue 文件通过 webpack 的 vue-loader 分析出 script style template 再走上面的 ES6 转 ES5 流程
- jsx 通过 babel 插件转 js 语法再走 ES6 转 ES5
- ts 通过 tsc 结合 tsconfig.json 直接转 ES5
# vite/esbuild/rollup 的关系
- Vite 是一个快速的前端构建工具,主要用于开发环境。它的主要特点包括:基于原生 ES 模块(ESM)能实现快速的冷启动,即时的模块热更新(HMR),真正的按需编译按需加载模块,无需像传统工具那样预构建整个项目,开箱即用无需复杂配置。使用 esbuild 作为开发阶段的快速依赖(如 node_modules 中的第三方库)预编译和转译(CommonJS->ESM)工具。使用 Rollup 作为生产构建的打包工具。所以 Vite 并不是简单的替代品,而是一个整合工具,结合了 esbuild 的速度和 Rollup 的灵活性,带来了高效的开发和生产构建体验。
- esbuild 是一个超高性能的 JavaScript 和 TypeScript 打包器和压缩器,它的主要特点是:使用 Go 语言编写,性能极高,得益于 Go 的性能和并行化设计,能快速实现代码转译和依赖预构建,支持 JavaScript 和 TypeScript,可以作为库使用,也可以作为独立的构建工具。提供基础的打包、转译和树摇(Tree Shaking)功能,支持现代 JavaScript/TypeScript 特性。注重单一职责,功能相对有限,主要用于快速构建和预编译。
- Rollup 是一个专注于现代 JavaScript 应用的模块打包器,专注于生产环境的构建。它的主要特点包括:生成更小、更高效的打包结果,支持 Tree-shaking、代码拆分、变量作用域提升等,有丰富的插件生态系统(如压缩、CSS 处理等)。支持 ES 模块(ESM),为现代 JavaScript 提供模块化的打包支持。Rollup 结合 JavaScript 引擎的死代码消除(依赖 DCE--Dead Code Elimination)优化,进一步减小输出文件的体积。
- 总结:vite 是基于 rollup 来实现的,包括开发服务器的 transform(会调用 rollup 插件的 transform 方法来做转换),以及生产环境的打包(也是用同样的 rollup 插件)。但是为了性能考虑,又用了 esbuild 做依赖预构建,比如把 cjs 转换成 esm、把小模块打包成一个大的模块。现在 vite 团队在开发 rust 版 rollup 也就是 rolldown 了,有了它之后,就可以完全替代掉 rollup + esbuild 了。
| 工具 | 适用场景 | 特点 | 插件系统 | 性能 |
|---|---|---|---|---|
| Vite | 开发和生产 | 开发阶段基于 ESM,生产阶段基于 Rollup,整合 esbuild 和 Rollup 优势 | 丰富(基于 Rollup) | 开发速度快,构建高效 |
| esbuild | 开发和快速构建 | 高速转译和打包,但功能简单,适合用作底层工具 | 简单 | 极快(使用 Go 实现) |
| Rollup | 生产构建 | 功能全面,支持复杂的生产环境优化,适合库开发和大规模项目 | 非常强大 | 高效,但比 esbuild 慢 |
PS:
- Tree-shaking 对于 动态导入 和 CommonJS 模块 支持有限,因为它们不能被静态分析。动态代码使用时(如动态计算导入路径)可能会导致无法移除未使用的代码。
- 代码拆分是一种优化技术,通过将代码分成多个模块(或文件),按需加载,从而减少初始页面加载的体积,并提高页面加载速度。常见应用场景:
- 按路由拆分代码(基于路由的懒加载)。
- 将共享依赖(如 react、lodash)分离到单独的文件中。
- Rollup 如何实现代码拆分?
- 动态导入(Dynamic Imports):Rollup 支持基于
import()的动态导入,将相关代码拆分为单独的 chunk 文件。依赖现代浏览器(需要支持 import())。 - 共享模块的提取:Rollup 使用
output.manualChunks配置,将共享依赖(如 node_modules 中的第三方库)提取为独立的 chunk。 - 按需加载:Rollup 将拆分的代码块输出为独立文件,结合现代模块加载器(如浏览器原生模块加载或 Webpack 的懒加载)实现按需加载。
- 动态导入(Dynamic Imports):Rollup 支持基于
- 什么是变量作用域提升?
- 变量作用域提升是一种优化技术,主要目标是将模块之间的代码整合到一个更大的作用域中,减少闭包的开销。
- 它可以避免不必要的函数包装,从而提高代码执行效率(尤其是对于浏览器中的解析和执行)。
- Rollup 如何实现作用域提升?
- Rollup 在打包过程中会将多个模块中的代码合并到一个共享作用域中,而不是为每个模块单独创建闭包。
- 这种优化得益于 Rollup 对 ESM 的静态分析能力,可以在打包阶段安全地将导入的模块“内联”到主模块中。
# 为什么普通 for 循环的性能远远高于 forEach 的性能
- forEach 需要额外的内存和函数调用,上下文作用域等等,所以会拖慢性能;for 循环没有任何额外的函数调用栈和上下文;
- 新版浏览器已经优化的越来越好,性能上的差异会越来越小
# 首屏优化
# 原因
- 硬件渲染能力有限,渲染时间长,首屏加载时间长,用户体验差;
- 网络延迟,加载速度慢
- 资源体积过大,导致加载慢
# 方法
- 减少入口文件体积:webpack 代码分割-多入口 entry+动态 import()导入+SplitChunksPlugin 插件 optimization.splitChunks+,
React.lazy+import()+Suspense,代码压缩,css 压缩去重,关键 CSS 提取直接内联插入到 html 中,tree-shaking(需要 ESM 标准代码) - 静态资源本地缓存或 cdn:OSS+CDN-比如 vue.config.js 中配置:configureWebpack.externals 把第三方库排除出打包结果后续在 html 中通过 CDN 引入,强缓存 Expire、Cache-Control:Max-Age=36000,协商缓存:Last-Modified/If-Modified-Since、Etag/If-None-Match,策略缓存:service-worker
- UI 框架、第三方库等按需加载:antd/es/xx、lodash-es 等,精简三方库,库内容按需导入使用
babel-plugin-import等插件,或者 shadcn 新型 UI 库,移除不必要的国际化文件,使用 React.memo 缓存组件渲染结果,使用 React.forwardRef 避免闭包, - 避免组件重复打包:提取公共组件,公共资源 vendors 抽离,使用
webpack-bundle-analyzer分析打包情况,通过 DllPlugin 将依赖单独打包(当公司没有很好的 CDN 资源或不支持 CDN 时,就可以考虑使用 DllPlugin,替换掉 externals,开发时项目启动也更快) - 图片资源压缩:tinyPNG 压缩图片、
url-loader转 icon 为 base64、雪碧图减少 http 请求,使用 webp 格式等, - 开启 gzip 压缩:webpack 使用:
compression-webpack-plugin插件配置相应的压缩算法、压缩文件类型、压缩后的文件名、文件体积临界值、压缩率等,Nginx 开启 gzip,通过Response Headers中可以看到Content-Encoding: gzip验证是否开启 - 使用 defer、async、importance 等关键字控制相应资源的加载优先级,首屏无关资源延迟加载或者用 preload、prefetch 进行预加载,prrender 预渲染,减少首屏白屏,滚动加载、可视区域局部渲染、
- 字体压缩:font-spider 移除无用字体,webfont 处理字体加载,fontmin 压缩字体等
- SSR 服务端渲染,首屏直出。局部 SSR。
- 后端优化接口响应速度,合并接口,减少请求次数,使用 http/2 服务端推送等技术。
提高打包速度:
- 由于运行在 Node.js 之上的 webpack 是单线程模型的,我们需要 webpack 能同一时间处理多个任务,发挥多核 CPU 电脑的威力,HappyPack 就能实现多线程打包,它把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程,来提升打包速度。
// vue.config.js
const HappyPack = require("happypack");
const os = require("os");
// 开辟一个线程池,拿到系统CPU的核数,happypack 将编译工作利用所有线程
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
module.exports = {
configureWebpack: {
plugins: [
new HappyPack({
id: "happybabel",
loaders: ["babel-loader"],
threadPool: happyThreadPool,
}),
],
},
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 预加载
<link rel="preload" href="./font/iconfont.woff2" as="font" type="font/woff2" crossorigin="anonymous" />
<link rel="preload" href="xxx.js" as="script" />
2
# 预渲染
Prerender 是前端工程化中一个概念,它指的是在服务器上渲染出完整的 HTML 页面,并返回给客户端,客户端收到页面后,再进行页面渲染。
比如:@prerender/webpack-plugin
# 打包体积分析
- webpack-bundle-analyzer
- vite-bundle-analyzer
# SSR
- React:Next.js
- Vue:Nuxt.js
# 白屏常见的优化方案有
- SSR
- 预渲染
- 骨架屏
# 首屏时间
- 首屏时间:指浏览器从响应用户输入网络地址,到首屏内容渲染完成的时间。也称用户完全可交互时间,即整个页面首屏完全渲染出来,用户完全可以交互,一般首屏时间小于页面完全加载时间,该指标值可以衡量页面访问速度。
- 白屏时间(First Paint):首次渲染时间,指页面出现第一个文字或图像所花费的时间。白屏时间是小于首屏时间的。
# 如何计算首屏时间
- 可以用最新 Performance API 获取首帧 FP、首屏 FCP
- 首次有意义的绘制 FMP 和 LCP、TTI:Time To Interactive,可交互时间,整个内容渲染完成等
- FMP:首次有意义绘制,指页面首次渲染完成,用户可以感知到的时间。可以用 MutationObserver 监听 DOM 变化,当 DOM 变化后,获取当前时间,作为 FMP 的时间戳。
- TTI: Time To Interactive,可交互时间,整个内容渲染完成等
- LCP:Largest Contentful Paint,页面中最大的内容绘制时间,指页面中最大的内容渲染完成,用户可以感知到的时间。可以用 IntersectionObserver 监听页面中的元素,当元素进入视口时,获取当前时间,作为 LCP 的时间戳。
- TBT:Total Blocking Time,总阻塞时间,指页面渲染过程中,阻塞用户交互的时间。可以用 Performance API 获取渲染开始时间,和用户交互时间,作为 TBT 的时间戳。
# SSR
- 在 SSR(服务端渲染)的应用中,我们认为 html 的 body 渲染完成的时间就是首屏时间。我们通常使用 W3C 标准的 Performance 对象来计算首屏时间。
- Performance 包含了四个属性:memory、navigation、timeOrigin、timing,以及一个事件处理程序 onresourcetimingbufferfull。
- 首屏时间:
domLoadedTime = timing.domContentLoadedEventStart - timing.navigationStart
# SPA
随着 Vue 和 React 等前端框架盛行,Performance 已无法准确的监控到页面的首屏时间。因为 DOMContentLoaded 的值只能表示空白页(当前页面 body 标签里面没有内容)加载花费的时间。浏览器需要先加载 JS , 然后再通过 JS 来渲染页面内容,这个时候单页面类型首屏才算渲染完成。
- 在 Lighthouse 中我们可以得到 FMP 值,FMP(全称 First Meaningful Paint,翻译为首次有效绘制)表示页面的主要内容开始出现在屏幕上的时间点,它是我们测量用户加载体验的主要指标。我们可以认为 FMP 的值就是首屏时间。
- 常见计算方式:
- 用户自定义打点—最准确的方式(只有用户自己最清楚,什么样的时间才算是首屏加载完成)。缺点:侵入业务,成本高。
- 粗略的计算首屏时间: loadEventEnd - fetchStart/startTime 或者 domInteractive - fetchStart/startTime
- 通过计算首屏区域内的所有图片加载时间,然后取其最大值
- 利用 MutationObserver 接口,监听 document 对象的节点变化,取 DOM 变化最大时间点为首屏时间,页面关闭时如果没有上报,立即上报
- window 监听 beforeunload 事件(当浏览器窗口关闭或者刷新时,会触发 beforeunload 事件)进行上报
# function 的 length
就是第一个具有默认值之前的参数个数,剩余参数是不算进 length 的计算之中的。
# CDN 原理&优势
DNS 域名服务器之所以分级(根、顶级、权威、本地)是为了通过负载均衡来分散压力,具体的域名解析都是由各自的权威域名服务器来处理的,根域名和顶级域名服务器只是做了个转发。
# CDN 原理
- CDN 不是一种协议,只是基于 DNS 协议实现的一种分布式网络。
- DNS 的流程是会先查找浏览器 DNS 缓存、hosts 文件、系统 DNS 缓存,然后请求本地 DNS 服务器,由它去一级级查询最终的 IP。
- CDN 是基于 DNS 的,在权威域名服务器做了 CNAME 的转发,然后根据请求 IP 的所在地来返回就近区域的服务器的 IP。这个流程是有一层层的缓存的,而且还是分布式的,是我们接触最多的高并发系统了。
# 优缺点
CDN 的核心点有两个,一个是缓存,一个是回源。“缓存”就是说我们把资源 copy 一份到 CDN 服务器上这个过程。“回源”就是说 CDN 发现自己没有这个资源(一般是缓存的数据过期了),转头向根服务器(或者它的上层服务器)去要这个资源的过程。
关于 CDN 缓存,在浏览器本地缓存失效后,浏览器会向 CDN 边缘节点发起请求。类似浏览器缓存,CDN 边缘节点也存在着一套缓存机制。CDN 边缘节点缓存策略因服务商不同而不同,但一般都会遵循 http 标准协议,通过 http 响应头中的
Cache-control: max-age的字段来设置 CDN 边缘节点数据缓存时间。当浏览器向 CDN 节点请求数据时,CDN 节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则 CDN 节点就会向服务器发出回源请求,从服务器拉取最新数据,更新本地缓存,并将最新数据返回给客户端。 CDN 服务商一般会提供基于文件后缀、目录多个维度来指定 CDN 缓存时间,为用户提供更精细化的缓存管理。
- CDN 优势
- CDN 节点解决了跨运营商和跨地域访问的问题,访问延时大大降低。用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
- 大部分请求在 CDN 边缘节点完成,CDN 起到了分流作用,减轻了源服务器的负载。
- CDN 提供冗余,有助于保护源服务器和内容。通过 CDN 的负载均衡和分布式存储技术,可以加强网站的可靠性,相当于无形中给网站添加了一把保护伞,可以缓解或防止常见的网络攻击,例如分布式拒绝服务(DDoS)攻击。
- 同一个域名下的请求会不分青红皂白地携带 Cookie,而静态资源往往并不需要 Cookie 携带什么认证信息。把静态资源和主页面置于不同的域名下,完美地避免了不必要的 Cookie 的出现!
- 远程访问用户根据 DNS 负载均衡技术智能自动选择 Cache 服务器
- 缺点
- 当源服务器资源更新后,如果 CDN 节点上缓存数据还未过期,用户访问到的依旧是过期的缓存资源,这会导致用户最终访问出现偏差。因此,开发者需要手动刷新相关资源,使 CDN 缓存保持为最新的状态。
# 简述 bundless 的优势与不足
# 优势
- 项目启动快。因为不需要过多的打包,只需要处理修改后的单个文件,所以响应速度是 O(1) 级别,刷新即可即时生效,速度很快。
- 浏览器加载块。利用浏览器自主加载的特性,跳过打包的过程。
- 本地文件更新,重新请求单个文件。
# 缺点
兼容性略差
# 什么是 semver,~ 与 ^ 的区别
semver,Semantic Versioning 语义化版本的缩写,文档可见 https://semver.org/,它由 [major, minor, patch] 三部分组成,其中:
- major: 当你发了一个含有 Breaking Change 的 API
- minor: 当你新增了一个向后兼容的功能时
- patch: 当你修复了一个向后兼容的 Bug 时
- 对于 ~1.2.3 而言,它的版本号范围是 [1.2.3, 1.3.0)
- 对于 ^1.2.3 而言,它的版本号范围是 [1.2.3, 2.0.0),可最大限度地在向后兼容与新特性之间做取舍
# 自动发现更新
- 升级版本号,最不建议的事情就是手动在 package.json 中进行修改。毕竟,你无法手动发现所有需要更新的 package。
- 可借助于
npm outdated,发现有待更新的 package。仍然需要手动在 package.json 更改版本号进行升级。 - 使用
npm outdated,还可以列出其待更新 package 的文档。npm outdated -l - 推荐一个功能更强大的工具
npm-check-updates,比npm outdated强大百倍。 npx npm-check-updates -u,可自动将 package.json 中待更新版本号进行重写。- 升级
[minor]小版本号,有可能引起 Break Change,可仅仅升级到最新的 patch 版本。npx npm-check-updates --target patch
# 如何修复某个 npm 包的紧急 bug
使用 patch-package,例如:
# 修改 lodash 的一个小问题
vim node_modules/lodash/index.js
# 对 lodash 的修复生成一个 patch 文件,位于 patches/lodash+4.17.21.patch
npx patch-package lodash
# 将修复文件提交到版本管理之中
git add patches/lodash+4.17.21.patch
git commit -m "fix 一点儿小事 in lodash"
# 此后的命令在生产环境或 CI 中执行
# 此后的命令在生产环境或 CI 中执行
# 此后的命令在生产环境或 CI 中执行
# 在生产环境装包
npm i
# 为生产环境的 lodash 进行小修复
npx patch-package
# 大功告成!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# package.json 中的字段及含义/作用
简单地就不说了
- main:npm package 的入口文件,当我们对某个 package 进行导入时,实际上导入的是 main 字段所指向的文件。main 是 CommonJS 时代的产物,也是最古老且最常用的入口文件。main 字段作为 commonjs 入口。
- module:module 字段作为 es module 入口。使用 import 对该库进行导入,则首次寻找 module 字段引入,否则引入 main 字段。
- exports 可以更容易地控制子目录的访问路径,也被称为 export map。可以根据模块化方案不同选择不同的入口文件,还可以根据环境变量(NODE_ENV)、运行环境(nodejs/browser/electron) 导入不同的入口文件。(相当于设个唯一别名?)
- browserslist:设置运行时浏览器版本
- sideEffects:false:开启 tree shaking-没有文件有副作用,全都可以 tree-shaking;true:关闭 tree shaking,所有文件都有副作用,全都不可 tree-shaking;[]:列出有副作用的文件不进行 tree-shaking,其他都可以 tree-shaking。
- lint-staged:设置 git commit 时需要格式化的文件和所用的工具
- husky:设置 git hooks
- engines:engines 字段中指定 Node 版本号
# dependencies 与 devDependencies 有何区别
对于业务代码而讲,它俩区别不大,打包时 webpack、Rollup 会对代码进行模块依赖分析,与该模块是否在 dep/devDep 并无关系,只要在 node_modules 上能够找到该 Package 即可。
对于库 (Package) 开发而言,是有严格区分的,当在项目中安装一个依赖的 Package 时,该依赖的 dependencies 也会安装到项目中,即被下载到 node_modules 目录中。但是 devDependencies 不会。
- dependencies: 在生产环境中使用
- devDependencies: 在开发环境中使用,如 webpack/babel/eslint 等
# package-lock.json 有什么作用
packagelock.json / yarn.lock用以锁定版本号,保证开发环境与生产环境的一致性,避免出现不兼容 API 导致生产环境报错。lockfile 对于第三方库仍然必不可少。
- 第三方库的 devDependencies 必须在 lockfile 中锁定,这样 Contributor 可根据 lockfile 很容易将项目跑起来。
- 第三方库的 dependencies 虽然有可能存在不可控问题,但是可通过锁死 package.json 依赖或者勤加更新的方式来解决。
# 简述 npm script 的生命周期
除了可自定义 npm script 外,npm 附带许多内置 scripts,他们无需带 npm run,可直接通过 npm <script> 执行。如:npm test/install/publish。
# npm cache
npm 会把所有下载的包,保存在用户文件夹下面。~/.npm或%AppData%/npm-cache等。
npm install 之后会计算每个包的 sha1 值(PS:安全散列算法(Secure Hash Algorithm)),然后将包与他的 sha1 值关联保存在 package-lock.json 里面,下次 npm install 时,会根据 package-lock.json 里面保存的 sha1 值去文件夹里面寻找包文件,如果找到就不用从新下载安装了。
npm cache verify:重新计算,磁盘文件是否与 sha1 值匹配,如果不匹配可能删除。要对现有缓存内容运行脱机验证,请使用 npm cache verify。npm cache clean --force:删除磁盘所有缓存文件。
# 一个 npm script 的生命周期
当我们执行任意 npm run 脚本时,将自动触发 pre/post 的生命周期。
比如:当手动执行 npm run abc 时,将在此之前自动执行 npm run preabc,在此之后自动执行 npm run postabc。
执行 npm publish,将自动执行以下脚本:
- prepublishOnly: 最重要的一个生命周期。如需要在发包之前自动做一些事情,如测试、构建等,请在 prepulishOnly 中完成。
- prepack
- prepare: 最常用的生命周期。
npm install之后自动执行,npm publish之前自动执行。 - postpack
- publish
- postpublish
- 发包实际上是将本地 package 中的所有资源进行打包,并上传到 npm 的一个过程。你可以通过
npm pack命令查看详情
# npm script 钩子的风险
有很多 npm package 被攻击后,就是通过 npm postinstall 自动执行一些事,比如挖矿等。
# 总结 npm run script 时发生了什么
- 表面上:
npm run xxx的时候,首先会去项目的 package.json 文件里找 scripts 里找对应的 xxx,然后执行 xxx 的命令,例如启动 vue 项目npm run serve的时候,实际上就是执行了vue-cli-service serve这条命令。 - 实际上:
vue-cli-service这条指令不存在操作系统中,我们在安装依赖的时候,是通过 npm i xxx 来执行的,例如npm i @vue/cli-service,npm 在 安装这个依赖的时候,就会在node_modules/.bin/目录中创建好vue-cli-service为名的几个可执行文件,实际是些软链接/node 脚本。 - 从
package-lock.json中可知,当我们npm i整个新建的 vue 项目的时候,npm 将bin/vue-cli-service.js作为 bin 声明了。 所以在npm install时,npm 读到该配置后,就将该文件软链接到./node_modules/.bin目录下,而 npm 还会自动把node_modules/.bin加入$PATH,这样就可以直接作为命令运行依赖程序和开发依赖程序,不用全局安装了。如果把包安装在全局环境,那么就可以直接使用这个命令。 - 也就是说,
npm i的时候,npm 就帮我们把这种软连接配置好了,其实这种软连接相当于一种映射,执行npm run xxx的时候,就会到node_modules/.bin中找对应的映射文件,如果没找到就去全局找,然后再找到相应的 js 文件来执行。 - 为什么
node_modules/bin中 有三个vue-cli-service文件? -- 在不同的系统中执行不同的脚本(跨平台执行)
- 运行
npm run xxx的时候,npm 会先在当前目录的node_modules/.bin查找要执行的程序,如果找到则运行; - 没有找到则从全局的
node_modules/.bin中查找,npm i -g xxx就是安装到到全局目录; - 如果全局目录还是没找到,那么就从 path 环境变量中查找有没有其他同名的可执行程序。
# npm i 时发生了什么
npm 模块安装机制
- npm install 执行后,会检查并获取 npm 配置,优先级为:
项目级别的.npmrc文件 > 用户级别的.npmrc文件 > 全局的.npmrc文件 > npm内置的.npmrc文件,查看配置命令:npm config ls -l。 - 然后检查项目中是否有 package-lock.json 文件。
- 如果有,检查 package-lock.json 和 package.json 中声明的依赖是否一致
- 一致:直接使用 package-lock.json 中声明的依赖,从缓存或者网络中加载依赖
- 不一致:各个版本的 npm 处理方式:

- 如果没有,根据 package.json 递归构建依赖树,然后根据依赖树下载完整的依赖资源,在下载时会检查是否有相关的资源缓存
- 存在:将缓存资源解压到 node_modules 中
- 不存在:从远程仓库下载资源包,并校验完整性,并添加到缓存,同时解压到 node_modules 中
- 如果有,检查 package-lock.json 和 package.json 中声明的依赖是否一致
- 最后生成 package-lock.json 文件。
- 构建依赖树时,不管是直接依赖还是子依赖,都会按照扁平化的原则,优先将其放置在 node_modules 根目录中(最新的 npm 规范)。在这个过程中,如果遇到相同的模块,会检查已放置在依赖树中的模块是否符合新模块的版本范围——如果符合,则跳过;不符合,则在当前模块的 node_modules 下放置新模块。
- npm 安装依赖时,会下载到缓存.npm 当中,然后解压到项目的 node_modules 中。
- 再次安装依赖的时候,会根据 package-lock.json 中存储的 integrity、version、name 信息生成一个唯一的 key,然后拿着 key 去目录中查找对应的缓存记录,如果有缓存资源,就会找到 tar 包的 hash 值,根据 hash 再去找缓存的 tar 包,并把对应的二进制文件解压到相应的项目 node_modules 下面,省去了网络下载资源的开销。
# 获取缓存位置
npm config get cache
# /Users/eric/.npm
# 清除缓存
npm cache clean --force
2
3
4
5
6
- 另外 npm-cache 文件夹中不包含全局安装的包,所以想清除存在问题的包为全局安装包时,需用
npm uninstall -g <package>解决 - npm 工程钩子生命周期:
preinstall、install、postinstall、prepublish、prepare
# npm 实现原理
输入 npm install 命令并敲下回车后,会经历如下几个阶段(以 npm 5.5.1 为例):
- 执行工程自身 preinstall
- 当前 npm 工程如果定义了 preinstall 钩子此时会被执行。
- 确定首层依赖模块
- 首先需要做的是确定工程中的首层依赖,也就是 dependencies 和 devDependencies 属性中直接指定的模块(假设此时没有添加 npm install 参数)。
- 工程本身是整棵依赖树的根节点,每个首层依赖模块都是根节点下面的一棵子树,npm 会开启多进程从每个首层依赖模块开始逐步寻找更深层级的节点。
- 获取模块
- 获取模块是一个递归的过程,分为以下几步:
- 获取模块信息。在下载一个模块之前,首先要确定其版本,这是因为 package.json 中往往是 semantic version(semver,语义化版本)。此时如果版本描述文件(npm-shrinkwrap.json 或 package-lock.json)中有该模块信息直接拿即可,如果没有则从仓库获取。如 packaeg.json 中某个包的版本是 ^1.1.0,npm 就会去仓库中获取符合 1.x.x 形式的最新版本。
- 获取模块实体。上一步会获取到模块的压缩包地址(resolved 字段),npm 会用此地址检查本地缓存,缓存中有就直接拿,如果没有则从仓库下载。
- 查找该模块依赖,如果有依赖则回到第 1 步,如果没有则停止。
- 模块扁平化(dedupe)
- 上一步获取到的是一棵完整的依赖树,其中可能包含大量重复模块。比如 A 模块依赖于 loadsh,B 模块同样依赖于 lodash。在 npm3 以前会严格按照依赖树的结构进行安装,因此会造成模块冗余。
- 从 npm3 开始默认加入了一个 dedupe 的过程。它会遍历所有节点,逐个将模块放在根节点下面,也就是 node-modules 的第一层。当发现有重复模块时,则将其丢弃。
- 这里需要对重复模块进行一个定义,它指的是模块名相同且 semver 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,而不必版本号完全一致,这可以使更多冗余模块在 dedupe 过程中被去掉。
- 比如 node-modules 下 foo 模块依赖 lodash@^1.0.0,bar 模块依赖 lodash@^1.1.0,则 ^1.1.0 为兼容版本。
- 而当 foo 依赖 lodash@^2.0.0,bar 依赖 lodash@^1.1.0,则依据 semver 的规则,二者不存在兼容版本。会将一个版本放在 node_modules 中,另一个仍保留在依赖树里。
举个例子,假设一个依赖树原本是这样:
node_modules
-- foo
---- lodash@version1
-- bar
---- lodash@version2
假设 version1 和 version2 是兼容版本,则经过 dedupe 会成为下面的形式:
node_modules
-- foo
-- bar
-- lodash(保留的版本为兼容版本)
假设 version1 和 version2 为非兼容版本,则后面的版本保留在依赖树中:
node_modules
-- foo
-- lodash@version1
-- bar
---- lodash@version2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 安装模块
- 这一步将会更新工程中的 node_modules,并执行模块中的生命周期函数(按照 preinstall、install、postinstall 的顺序)。
- 执行工程自身生命周期
- 当前 npm 工程如果定义了钩子此时会被执行(按照 install、postinstall、prepublish、prepare 的顺序)。
- 最后一步是生成或更新版本描述文件,npm install 过程完成。
# 软链接和硬链接
- 通过 ln -s 创建一个软链接,通过 ln 可以创建一个硬链接。
- 区别有以下几点:
- 软链接可理解为指向源文件的指针,它是单独的一个文件,仅仅只有几个字节,它拥有独立的 inode
- 硬链接与源文件同时指向一个物理地址,它与源文件共享存储数据,它俩拥有相同的 inode
- pnpm 为何节省空间:
- 解决了 npm/yarn 平铺 node_modules 带来的依赖项重复的问题 (doppelgangers)
- 在 pnpm 中,它改变了 npm/yarn 的目录结构,采用软链接的方式,避免了 doppelgangers 问题更加节省空间。
- 通过硬链接,又能使多个不同的项目复用相同依赖的存储空间。
# 如何确保所有 npm install 的依赖都是安全的?
- Audit,审计,检测你的所有依赖是否安全。
npm audit / yarn audit均有效。通过审计,可看出有风险的 package、依赖库的依赖链、风险原因及其解决方案。 - 通过
npm audit fix可以自动修复该库的风险,原理就是升级依赖库,升级至已修复了风险的版本号。npm audit fix yarn audit无法自动修复,需要使用yarn upgrade手动更新版本号,不够智能。- synk 是一个高级版的
npm audit,可自动修复,且支持 CICD 集成与多种语言。npx snyk,npx wizard,npx snyk wizard
# Long Term Cache
- 通过在服务器端/网关端对资源设置以下 Response Header,进行强缓存一年时间,称为永久缓存,即 Long Term Cache。
Cache-Control: public,max-age=31536000,immutable - 假设有两个文件: index.js 和 lib.js,且 index 依赖于 lib,由 webpack 打包后将会生成两个 chunk --
index.aaaaaa.js和lib.aaaaaa.js,假设 lib.js 文件内容发生变更,index.js 由于引用了 lib.js,可能包含其文件名,那么它的 hash 是否会发生变动?
- 不一定。打包后的 index.js 中引用 lib 时并不会包含 lib.aaaaaa.js,而是采用 chunkId 的形式,如果 chunkId 是固定的话(chunkIds = deterministic 时),则不会发生变更。即在 webpack 中,通过
optimization.chunkIds = 'deterministic'可设置确定的 chunkId,来增强 Long Term Cache 能力。此时打包,仅仅 lib.js 路径发生了变更 --lib.bbbbbb.js。
# 设计模式
# 工厂模式
生成一个函数,return 一个实例,每次需要生成实例的时候直接调这个函数即可,而不需要 new。
# 单例模式
生成一个全局唯一的实例且不能生成第二个,比如 Redux、Vuex 的 store 或者全局唯一的 dialog、modal 等。例:js 是单线程的,创建单例很简单
class SingleTon {
private static instance: SingleTon | null = null;
private constructor() {}
public static getInstance(): SingleTon {
if (this.instance === null) {
this.instance = new SingleTon();
}
return this.instance;
}
fn1() {}
fn2() {}
}
const sig = SingleTon.getInstance();
sig.fn1();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 代理模式
Proxy:在对象之间架设一个拦截层,对一些操作进行拦截和处理。
# 观察者模式
一个主题,一个观察者,主体变化后触发观察者执行:btn.addEventListener('click',()=>{...}),Subject 和 Observer 直接绑定,没有中间媒介。
# 发布订阅模式
订阅/绑定一些事件eventBus.on('event1',()=>{});,然后发布/触发这些事件eventBus.emit('event1',props);,绑定的事件在组件销毁时记得删除解绑。Publisher 和 Observer 互不认识,需要中间媒介 Event Channel。
和观察者模式的区别: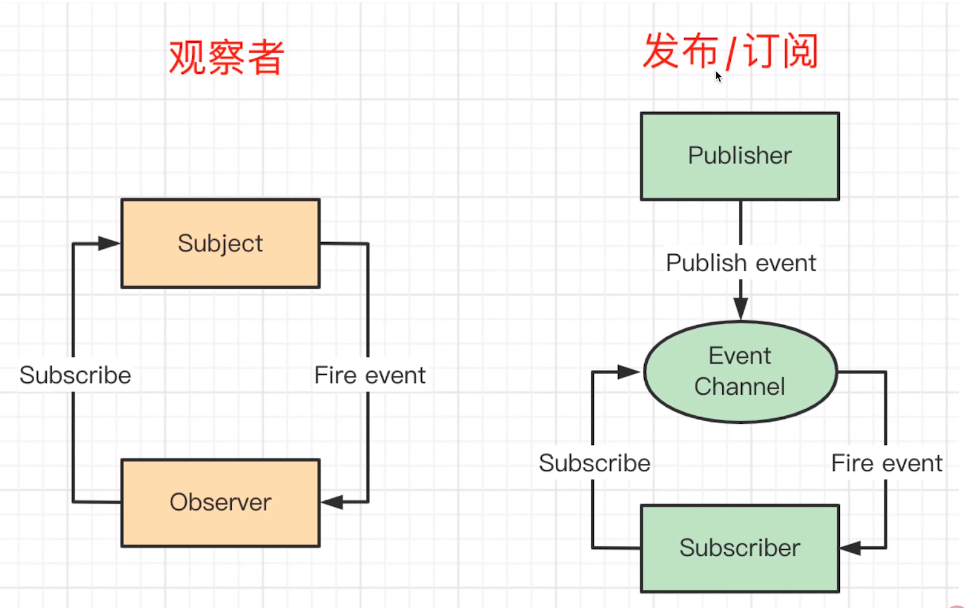
# 装饰器模式
Decorator:装饰类或者方法,不会修改原有的功能,只是增加一些新功能(AOP 面向切面编程)。
# 面试题
# 手写 AST 的 demo
function add(a, b) {
return a + b;
}
// 转化为下面的AST代码
const ast = {
type: "Program",
body: [
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "add",
},
params: [
{
type: "Identifier",
name: "a",
},
{
type: "Identifier",
name: "b",
},
],
body: {
type: "BlockStatement",
body: [
{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "+",
left: {
type: "Identifier",
name: "a",
},
right: {
type: "Identifier",
name: "b",
},
},
},
],
},
},
],
sourceType: "script",
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 手写 VDOM 的 demo
const vdom = {
tag: "div",
attrs: { id: "app" },
children: [
{
tag: "h1",
attrs: null,
children: ["Hello, Virtual DOM!"],
},
{
tag: "p",
attrs: null,
children: ["This is a simple implementation."],
},
],
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 前端重新加载/刷新页面
location.reload()location.reload(true):强制从服务器重新加载页面而不是从缓存中加载location.href = location.hrefhistory.go(0)<meta http-equiv="refresh" content="30">:用于特定的场景,如当页面需要在一定时间后自动更新
# 2022-04-27 万向区块链
# 关于堆和栈、一级缓存和二级缓存的理解
- 数据结构的堆和栈(都是逻辑结构)
- 堆:先进先出的,可以被看成是一棵树,如:堆排序。
- 栈:后进先出的、自顶向下。
- 内存分布上的堆和栈
- 栈:局部变量的内存,函数结束后内存自动被释放,栈内存分配运算内置于处理器的指令集中,它的运行效率一般很高,但是分配的内存容量有限。
- 静态存储区:全局变量、static 变量;它是由编译器自动分配和释放的,即内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在,直到整个程序运行结束时才被释放。
- 动态储存区:堆和栈
- 一级缓存和二级缓存
- 栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。栈的效率比堆的高。
- 堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
- 为什么需要缓存?
- cpu 运行速率很快,但内存的速度很慢,所以就需要缓存,缓存分为一级二级三级,越往下优先级越低,成本越低,容量越大。
- 栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收,分配方式倒是类似于链表。
- CPU 读写速率:
- 寄存器>一级缓存>二级缓存
# Vue 和 React 的区别
- 原理实现上的区别
- 使用上的区别
- 性能上的区别
- 周边生态的区别
# Vue 和 React 的生命周期
- Vue2 的生命周期:beforeCreate -> created -> beforeMount -> mounted -> beforeUpdate -> updated -> beforeDestroy -> destroyed,activated -> deactivated,errorCaptured。
- Vue3 的生命周期:setup -> onBeforeMount -> onMounted -> onBeforeUpdate -> onUpdated -> onBeforeUnmount -> onUnmounted -> onActivated -> onDeactivated -> onErrorCaptured -> onRenderTracked(dev only) -> onRenderTriggered(dev only) -> onServerPrefetch(SSR only)。
- React 的生命周期:constructor(props) -> static getDerivedStateFromProps(nextProps, prevState) ->
componentWillMount-> render -> componentDidMount ->componentWillReceiveProps-> shouldComponentUpdate(nextProps, nextState) -> render ->componentWillUpdate-> getSnapshotBeforeUpdate(prevProps, prevState) -> componentDidUpdate(prevProps, prevState, snapshot) -> componentWillUnmount。
# React
- 挂载阶段:
当组件实例被创建并插入 DOM 中时,其生命周期调用顺序如下:
constructor()static getDerivedStateFromProps()render()componentDidMount()
- 更新阶段:
当组件中的 props 或者 state 发生变化时就会触发更新。组件更新的生命周期调用顺序如下:
static getDerivedStateFromProps()shouldComponentUpdate()render()getSnapshotBeforeUpdate()componentDidUpdate()
- 卸载:
componentWillUnmount()
- 废弃的钩子:
componentWillMountcomponentWillReceivePropscomponentWillUpdate
# Vue 和 React 渲染组件的方式有何区别
React 渲染机制
- 虚拟 DOM:React 使用虚拟 DOM 来提高性能。组件的状态或属性改变时,React 会先在虚拟 DOM 中计算出差异(diffing),然后再将变化应用于实际的 DOM。
- 组件生命周期:React 通过生命周期方法(如
componentDidMount、shouldComponentUpdate等)来控制组件的渲染和更新。 - 单向数据流:React 的数据流是单向的,组件通过 props 接收数据,状态变化会触发重新渲染。
- 组件通常使用 JavaScript 函数或类来定义,采用 JSX 语法书写 UI。
- 组件的渲染依赖于
render()方法或函数返回 JSX。 - 使用
shouldComponentUpdate()方法或React.memo()进行组件更新优化。 - 在大型应用中,通过
React.lazy和React.Suspense实现代码分割和懒加载。
Vue 渲染机制
- 响应式系统:Vue 使用响应式数据绑定,数据变化时,视图会自动更新,而不需要手动处理 DOM 更新。Vue 内部使用了
Object.defineProperty/Proxy拦截 属性/对象 的 getter/setter 来实现数据的观察。 - 虚拟 DOM:Vue 也使用虚拟 DOM,但它的实现方式相对 React 更加简洁。Vue 在渲染过程中会生成一个虚拟 DOM 树并进行 diffing,最终将最小的差异应用于实际的 DOM。
- 双向数据绑定:Vue 支持双向数据绑定,通过 v-model 等指令,可以在视图和数据之间建立直接的双向绑定。
- 组件定义通常使用 .vue 文件,包含
<template>、<script>和<style>三个部分。 - 组件的渲染通过模板语言定义,使用 Vue 的指令(如
v-if、v-for)来实现。 - 通过
v-once、v-memo等指令进行性能优化,避免不必要的重新渲染。 - 使用计算属性(computed properties)和侦听器(watchers)来优化数据更新和视图渲染。
# React.lazy 和 React.Suspense
React.lazy 是一个函数,用于定义动态导入的组件。它允许你按需加载组件,而不是在应用启动时一次性加载所有组件,从而减少初始加载时间。React.lazy 只能用于组件,不能用于普通的 JavaScript 函数。
- 代码分割:React.lazy 使用 Webpack 的动态导入功能,将组件分割成独立的代码块。当组件被需要时,才会加载这个代码块。
- 懒加载:它返回一个可以在渲染时使用的 React 组件。这种组件在第一次渲染时不会立即加载,而是等到真正需要显示该组件时才加载。
const MyComponent = React.lazy(() => import("./MyComponent"));
React.Suspense 是一个组件,用于处理懒加载组件时的加载状态。它允许你指定一个 fallback 属性,即在组件加载过程中显示的内容(通常是加载指示器或占位符)。在使用 Suspense 时,建议结合错误边界(Error Boundaries)来处理加载过程中的错误。这样可以保证如果组件加载失败,可以优雅地处理错误情况。在 React 18 中,Suspense 还可以配合新的数据获取 API 使用,更加增强了异步和并发渲染的能力。
- 加载状态管理:当使用 React.lazy 加载组件时,React 会在组件加载的过程中触发 Suspense 的加载状态。React.Suspense 会捕获这个加载状态,并在组件加载完成之前显示 fallback 内容。
- Promise 处理:当 React.lazy 返回的 Promise 被解析时,Suspense 会重新渲染其子组件,以显示加载完成后的内容。
- 并发特性:在 React 18 及以后的版本中,Suspense 还与并发特性结合,使得在数据获取和渲染过程中,React 可以更智能地处理 UI 更新。
<React.Suspense fallback={<div>Loading...</div>}>
<MyComponent />
</React.Suspense>
2
3
# 哪个 React 生命周期可以跳过子组件渲染
- React 类组件中:
shouldComponentUpdate(nextProps, nextState) {return nextProps.value !== this.props.value;},只在特定条件下更新。 - 函数组件中:使用
React.memo()来包裹组件,通过传入一个比较函数来决定是否更新。
const MyComponent = React.memo(
({ value }) => {
return <div>{value}</div>;
},
(prevProps, nextProps) => {
return prevProps.value === nextProps.value; // 如果值相等,不更新
}
);
2
3
4
5
6
7
8
# React 类组件中的 setState 和函数组件中 setState 的区别
# React 的 Reconciliation 过程是如何工作的
# forEach 和 map 的区别
# Proxy 概念
# Reflect 概念
# Symbol 概念
# 防抖、节流
# 重绘与重排
回流是指浏览器需要重新计算样式、布局定位、分层和绘制,回流又被叫重排;触发回流的操作:
- 添加或删除可见的 DOM 元素
- 元素的位置发生变化
- 元素的尺寸发生变化
- 浏览器的窗口尺寸变化
- 修改字体会引起重排
重绘是只重新像素绘制,当元素样式的改变不影响布局时触发。
回流=计算样式+布局+分层+绘制;重绘=绘制。故回流对性能的影响更大。
# JS 中 new 一个对象的过程
- 使用 Object.create
- 以构造函数 Parent 的 prototype 属性为原型,创建一个新的空对象 obj:
const obj = Object.create(Parent.prototype); - 将 obj 作为 this,并传入参数,执行构造函数:
Parent.apply(obj, args); - 返回 obj(如果构造器没有手动返回对象,则返回第一步的对象):
return obj;
function MockNew(Parent, ...args) {
const obj = Object.create(Parent.prototype);
const result = Parent.apply(obj, args);
return typeof result === "object" ? result : obj;
}
2
3
4
5
- 不使用 Object.create
- 创建一个空对象 obj:
const obj = {}; - 让 obj 继承构造函数的的原型 prototype,即将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象):
obj.proto = Parent.prototype; - 将 obj 作为 this,并传入参数,执行构造函数:
Parent.apply(obj, args); - 返回 obj(如果构造器没有手动返回对象,则返回第一步的对象):
return obj;
function MockNew(Parent, ...args) {
const obj = {};
obj.proto = Parent.prototype;
const result = Parent.apply(obj, args);
return typeof result === "object" ? result : obj;
}
2
3
4
5
6
{}创建空对象,原型__proto__指向 Object.prototypeObject.create创建空对象,原型__proto__指向传入的参数(构造函数或者 null)
# 宏任务与微任务
JS 引擎是单线程的,一个时间点下 JS 引擎只能做一件事。而事件循环 Event Loop 是 JS 的执行机制。
JS 做的任务分为同步和异步两种,所谓 "异步",简单说就是一个任务不是连续完成的,先执行第一段,等做好了准备,再回过头执行第二段,第二段也被叫做回调;同步则是连贯完成的。
在等待异步任务准备的同时,JS 引擎去执行其他同步任务,等到异步任务准备好了,再去执行回调。这种模式的优势显而易见,完成相同的任务,花费的时间大大减少,这种方式也被叫做非阻塞式。
而实现这个“通知”的,正是事件循环,把异步任务的回调部分交给事件循环,等时机合适交还给 JS 线程执行。事件循环并不是 JavaScript 首创的,它是计算机的一种运行机制。
事件循环是由一个队列组成的,异步任务的回调遵循先进先出,在 JS 引擎空闲时会一轮一轮地被取出,所以被叫做循环。
微任务和宏任务皆为异步任务,它们都属于一个队列,主要区别在于他们的执行顺序,Event Loop 的走向和取值。
事件循环由宏任务和在执行宏任务期间产生的所有微任务组成。完成当下的宏任务后,会立刻执行所有在此期间入队的微任务。
这种设计是为了给紧急任务一个插队的机会,否则新入队的任务永远被放在队尾。区分了微任务和宏任务后,本轮循环中的微任务实际上就是在插队,这样微任务中所做的状态修改,在下一轮事件循环中也能得到同步。
async 函数在 await 之前的代码都是同步执行的,可以理解为 await 之前的代码属于 new Promise 时传入的代码,await 之后的所有代码都是在 Promise.then 中的回调。
# setState 是宏任务还是微任务
- setState 本质是同步执行,state 都是同步更新,只不过让 React 做成了异步的样子--为了性能优化,会批量处理多次状态更新,合并状态变化,在批量更新结束后,React 会根据最终的状态触发一次重新渲染,React 根据更新后的状态和虚拟 DOM 计算出需要更新的部分,并重新渲染组件。
- 比如在 setTimeout 中时,就是同步,比如在 Promise.then 开始之前,state 已经计算完了。
- 因为要考虑性能优化,多次修改 state,只进行一次 DOM 渲染。
- 日常说的异步是不严谨的,但沟通成本低。
- 所以,既不是宏任务也不是微任务,因为它是同步的。
React 的 合成事件 和 生命周期 默认启用了批处理机制。 在这种情况下,setState 不会立即更新,而是将更新加入到一个队列中,待所有事件回调或生命周期方法执行完后才开始处理。 这种延迟更新可以理解为 任务被加入到下一轮的任务队列中,但它既不是纯粹的宏任务,也不是纯粹的微任务,而是由 React 内部调度机制控制的。
因此:在 React 内部合成事件和生命周期方法中,setState 的更新并不会立即生效,而是会被批量处理。它的行为更类似于 宏任务,因为它通常会在事件循环的下一阶段触发更新,但由 React 内部控制。
在原生事件或异步回调中,如果在 原生事件 或 Promise.then 中调用 setState,React 的批处理机制不会生效,状态更新可能会立即触发,视具体场景而定。在这种情况下,setState 的行为更接近微任务。
不要依赖 setState 后立即获取更新后的状态值,使用 useEffect 或回调函数(如 setState((prevState) => newState))。理解 React 的批量更新机制,避免不必要的状态更新。
// 原生事件中
document.getElementById("btn").addEventListener("click", () => {
setState({ count: count + 1 });
console.log(state.count); // 可能会立即更新
});
// Promise.then 中
Promise.resolve().then(() => {
setState({ count: count + 1 });
console.log(state.count); // 可能会更新
});
2
3
4
5
6
7
8
9
10
11
# 闭包的优缺点
- 闭包是指有权访问另一个函数作用域中变量的函数。创建闭包最常见的方式就是,在一个函数内部创建并返回另一个函数。当函数能够记住并访问所在的词法作用域时,就产生了闭包。
- 闭包通常用来创建内部/私有变量,使得 这些变量不能被外部随意修改,同时又可以通过指定的接口来操作。
- 闭包也会用来延长变量的生命周期。
- 闭包其实是一种特殊的函数,它可以访问函数内部的变量,还可以让这些变量的值始终保持在内存中,不会在函数调用后被垃圾回收机制清除。
- 优点:
- 包含函数内变量的安全,实现封装,防止变量流入其他环境发生命名冲突,造成环境污染。
- 在适当的时候,可以在内存中维护变量并缓存,提高执行效率。
- 即可以用来传递、缓存变量,使用合理,一定程度上能提高代码执行效率。
- 缺点:
- 函数拥有的外部变量的引用,在函数返回时,该变量仍处于活跃状态。
- 闭包作为一个函数返回时,其执行上下文不会被销毁,仍处于执行上下文中。
- 即消耗内存,使用不当容易造成内存泄漏,性能下降。
- 常见使用:节流防抖、IIFE(自执行函数)、柯里化实现
# commonJs 中的 require 与 ES6 中的 import 的区别
# export 与 import 的区别
# CSS 加载是否阻塞 DOM 渲染
# 别人面试
昨天晚上面试题:
- webpack 编译过程
- webpack 热更新
- 从浏览器地址栏输入 url 到用户看到界面发生了什么
- http 的请求报文跟响应报文都有什么
- 说下 http 的缓存(强缓存,协商缓存)
- http 的短连接和长连接
- websocket 和长连接的区别
- 同域名下两个浏览器窗口的 数据共享
- 不同域名下两个浏览器窗口的 数据共享(主要是跟 iframe 的数据共享 )
- css 动画. 栅格布局,自适应布局
- call,apply,bind 的区别
- 闭包
- 柯里化函数
- 防抖,节流
- vue 父子通信的方式
- diff 原理
- vue 路由的实现,从地址改变到渲染组件发生了什么
- vue 的响应式原理
- vue 的生命周期,父子生命周期的顺序
- nextTick 的实现原理
- React.PureComponent 与 Component 的区别
PureComponent会默认实现在shouldComponentUpdate中对 props 的第一层属性做浅比较,然后决定是否更新,相当于做了个性能小优化。不能在PureComponent中使用shouldComponentUpdate。类似React.memo()。
- 如何统一监听 Vue 组件报错
window.onerror:全局监听所有 js 错误,可以捕捉 Vue 监听不到的错误;但它是 js 级别的,识别不了 Vue 组件信息;监听不到 try/catch,可以监听异步报错;window.addEventListener('error', function(){}):同上。参数略有不同。捕获的异常如何上报?常用的发送形式主要有两种: 通过 ajax 发送数据(xhr、jquery...)或动态创建 img 标签的形式;errorCaptured:(errmsg,vm,info)={}:在组件中配置(使用类似钩子函数);监听所有下级组件的错误;返回 false 会阻止向上传播;无法监听异步报错;errorHandler:(errmsg,vm,info)={}:在 main.js 中配置(使用类似钩子函数)app.config.errorHandler=()=>{};Vue 全局错误监听,所有错误都会汇总到这里;但errorCaptured返回 false,不会传播到这里;会干掉window.onerror;无法监听异步报错;
- 如何统一监听 React 组件报错
- 编写
ErrorBoundary组件:利用static getDerivedStateFromError钩子监听所有下级组件的错误,可降级展示 UI;只监听组件渲染时报错,不监听 DOM 事件、异步错误;降级展示只在 production 环境生效,dev 会直接抛出错误。 - 从上可知
ErrorBoundary不会监听 DOM 事件报错和异步错误,所以可以用try-catch,也可用window.onerror; - Promise 未处理的 catch 需要监听
onunhandledrejection:onerror 事件无法捕获到网络异常的错误(资源加载失败、图片显示异常等),例如 img 标签下图片 url 404 网络请求异常的时候,onerror 无法捕获到异常,此时需要监听unhandledrejection。 - JS 报错统计(埋点、上报、统计)用 sentry;sentry 是一个基于 Django 构建的现代化的实时事件日志监控、记录和聚合平台,主要用于快速的发现故障。sentry 支持自动收集和手动收集两种错误收集方法。我们能成功监控到 vue 中的错误、异常,但是还不能捕捉到异步操作、接口请求中的错误,比如接口返回 404、500 等信息,此时我们可以通过
Sentry.caputureException()进行主动上报。
- 编写
- 鉴权
- hmr 热更新原理
- mixin,vue router 的原理
- vue 双向绑定原理
- es6 的新特性
- 如何在 vite 工程的 ts 项目中配置路径别名?
// 1. 打开 vite.config.ts 文件,并导入 resolve 方法和 defineConfig 函数。
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import { resolve } from 'path';
export default defineConfig({
plugins: [vue()],
resolve: {
alias: {
'@': resolve(__dirname, 'src'), // 配置路径别名
},
},
});
// 2. 在 tsconfig.json 文件中添加如下配置:
{
"compilerOptions": {
"target": "esnext",
"module": "esnext",
"strict": true,
"jsx": "preserve",
"moduleResolution": "node",
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"baseUrl": ".",
"paths": {
"@/*": ["src/*"] // 添加路径别名
}
},
"include": ["src/**/*"]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 一个页面打开比较慢,怎么处理?
- 通过 Chrome 的 performance 面板或者 Lighthouse 等工具分析页面性能,通过查看 FP(首次渲染)、FCP(首次内容渲染)、DOMContentLoaded(DCL)、Largest Contentfull Paint 最大内容渲染(LCP)、Load(L)等性能指标,结合资源的加载情况,来判断是哪个过程有问题:加载过程慢还是渲染过程慢?
- 对于加载过程慢:说明是网络问题比较严重。
- 优化服务端硬件配置,静态资源上 cdn 或者是压缩图片、使用 base64 等减少请求数,服务端开启 gzip 等;
- 路由懒加载,大组件异步加载,减少主包的体积;
- 优化 http 缓存策略,强缓存、协商缓存,对于静态资源可以开启强缓存。
- 对于渲染过程慢:可能是接口数据返回的慢,也可能是代码写的有问题。
- 优化服务端接口,提高响应速度;
- 分析前端代码逻辑,优化 Vue/React 组件代码,比如减少重排重绘;
- 服务端渲染 SSR;
- 优化体验:骨架屏,加载动画、进度条。
- 持续跟进:
- 性能优化是一个循序渐进的过程,不像 bug 一次性解决;
- 持续跟进统计结果,再逐步分析性能瓶颈,持续优化;
- 可以使用第三方统计服务,如阿里云 ARMS,百度统计等;
# 大文件上传


- 采用分片上传,将大文件分割成多个小文件,并发上传。
- 采用断点续传,记录已上传的分片,下次上传时跳过已上传的分片。
- 采用多线程上传,充分利用多核 CPU 资源。
- 采用队列管理,控制并发上传数量,避免占用过多带宽。
- 采用服务端合并,将分片上传的结果进行合并,实现完整的文件上传。
# 如何实现一个 Promise
class MyPromise {
constructor(executor) {
this.status = "pending";
this.value = undefined;
this.reason = undefined;
this.onFulfilledCallbacks = [];
this.onRejectedCallbacks = [];
const resolve = (value) => {
if (this.status === "pending") {
this.status = "fulfilled";
this.value = value;
this.onFulfilledCallbacks.forEach((cb) => cb(value));
}
};
const reject = (reason) => {
if (this.status === "pending") {
this.status = "rejected";
this.reason = reason;
this.onRejectedCallbacks.forEach((cb) => cb(reason));
}
};
try {
executor(resolve, reject);
} catch (error) {
reject(error);
}
}
then(onFulfilled, onRejected) {
const promise2 = new MyPromise((resolve, reject) => {
if (this.status === "fulfilled") {
setTimeout(() => {
try {
const x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
} else if (this.status === "rejected") {
setTimeout(() => {
try {
const x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
} else if (this.status === "pending") {
this.onFulfilledCallbacks.push(() => {
setTimeout(() => {
try {
const x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
});
this.onRejectedCallbacks.push(() => {
setTimeout(() => {
try {
const x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
});
}
});
return promise2;
}
catch(onRejected) {
return this.then(null, onRejected);
}
}
function resolvePromise(promise2, x, resolve, reject) {
if (promise2 === x) {
reject(new TypeError("Chaining cycle detected"));
} else if (x instanceof MyPromise) {
if (x.status === "pending") {
x.then(
(value) => resolvePromise(promise2, value, resolve, reject),
(reason) => reject(reason)
);
} else {
x.then(resolve, reject);
}
} else {
resolve(x);
}
}
const p = new MyPromise((resolve, reject) => {
setTimeout(() => {
resolve("success");
}, 1000);
});
p.then((value) => {
console.log(value);
}).catch((reason) => {
console.log(reason);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# 中断 for 循环
- break 是最直接、常规的中断循环的方式。
- 在函数中:可以使用 return。注意:return 只能在函数内部使用。直接在浏览器里跑 for 循环会报错。
- 嵌套循环:可以使用 label 和 break。
- 替代方式:修改循环条件。比如把 i 加到最大。
- 不推荐:抛出异常。
拓展:js 中常见循环的中断方式:
- forEach:是数组方法,用于遍历数组的每一项,无法通过 break 或 continue 中断。中断方式:抛出异常;return 不会中断整个循环,只是跳过当前回调函数的执行。
- map:是数组方法,适用于对数组的每一项进行转换并生成新的数组。无法中断循环,但可以通过 return 提前返回当前项的处理结果或者抛出异常。
- reduce:用于将数组的每一项折叠为单一值,无法中断,但可以通过逻辑控制提前退出计算 - 提前 return。
- filter:用于筛选数组项,无法中断循环,但可以通过条件控制跳过某些项的逻辑处理。
- for...of:遍历可迭代对象(如数组、Set、Map 等)。可以使用 break、continue 和 return 来中断循环。break:终止整个循环;continue:跳过当前循环,继续下一次迭代;return:如果在函数体内,终止整个函数。
- for...in:用于遍历对象的可枚举属性(常用于对象,而非数组)。可以使用 break 和 continue 来控制循环。
- while:是标准的循环结构,可以使用 break、continue 和修改循环条件、抛出异常 来中断。
- do...while: 类似于 while,但会确保代码至少执行一次。可以使用 break 和 continue、抛出异常 来中断。break:终止整个循环;continue:跳过当前循环并检查条件;注意:在 do...while 中,continue 可能会导致死循环,建议谨慎使用。
- for:break、return、label、修改循环条件、抛出异常。
// 执行如下代码,输出:0 1 2 之后卡死。
let i = 0;
do {
if (i === 3) continue; // 跳过当前循环
console.log(i); // 输出会有问题,注意陷阱
i++;
} while (i < 5);
2
3
4
5
6
7
# 前端实现截图
两种情况:
- 对浏览器网页页面的截图。
- 仅对 canvas 画布的截图,比如可视化图表、webGL 等。
实现方式:
- 第三方库:html2canvas(Canvas)、dom-to-image(SVG) - 两种方案目标相同,即把 DOM 转为图片
- 对 canvas 画布截图,因为 canvas 它本身就有保存为图片的功能,它有两个 API 可以用来导出图片,分别是 toDataURL 和 toBlob。toDataURL 方法是将整个画布转换成 base64 格式的 url 地址,toBlob 方法是创造 Blob 对象,默认图片类型是 image/png。
- 浏览器原生截图 API:
navigator.mediaDevices.getUserMedia/getDisplayMedia,可以获取到屏幕的视频流,然后通过视频流生成截图。需要权限。
const a = async () => {
try {
// 调用屏幕捕获 API
const stream = await navigator.mediaDevices.getDisplayMedia({
video: { mediaSource: "screen" },
});
const track = stream.getVideoTracks()[0];
const imageCapture = new ImageCapture(track);
// 捕获屏幕截图
const bitmap = await imageCapture.grabFrame();
// 绘制到 Canvas
const canvas = document.createElement("canvas");
canvas.width = bitmap.width;
canvas.height = bitmap.height;
const ctx = canvas.getContext("2d");
ctx.drawImage(bitmap, 0, 0, bitmap.width, bitmap.height);
// 导出为图片
const imgData = canvas.toDataURL("image/png");
console.log(imgData);
// 停止捕获屏幕
track.stop();
// 如果需要下载图片
const link = document.createElement("a");
link.href = imgData;
link.download = "screenshot.png";
link.click();
} catch (err) {
console.error("屏幕捕获失败:", err);
}
};
a();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 数组和链表
# 区别
| 比较项 | 数组 | 链表 |
|---|---|---|
| 逻辑结构 | (1)数组在内存中连续; (2)使用数组之前,必须事先固定数组长度,不支持动态改变数组大小;(3) 数组元素增加时,有可能会数组越界;(4) 数组元素减少时,会造成内存浪费;(5)数组增删时需要移动其它元素 | (1)链表采用动态内存分配的方式,在内存中不连续 (2)支持动态增加或者删除元素 (3)需要时可以使用 malloc 或者 new 来申请内存,不用时使用 free 或者 delete 来释放内存 |
| 内存结构 | 数组从栈上分配内存,使用方便,但是自由度小 | 链表从堆上分配内存,自由度大,但是要注意内存泄漏 |
| 访问效率 | 数组在内存中顺序存储,可通过下标访问,访问效率高 | 链表访问效率低,如果想要访问某个元素,需要从头遍历 |
| 越界问题 | 数组的大小是固定的,所以存在访问越界的风险 | 只要可以申请得到链表空间,链表就无越界风险 |
# 使用场景
| 比较项 | 数组 | 链表 |
|---|---|---|
| 空间 | 数组的存储空间是栈上分配的,存储密度大,当要求存储的大小变化不大时,且可以事先确定大小,宜采用数组存储数据 | 链表的存储空间是堆上动态申请的,当要求存储的长度变化较大时,且事先无法估量数据规模,宜采用链表存储 |
| 时间 | 数组访问效率高。当线性表的操作主要是进行查找,很少插入和删除时,宜采用数组结构 | 链表插入、删除效率高,当线性表要求频繁插入和删除时,宜采用链表结构 |
# 操作系统中进程间通信 IPC
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。第一,进程是一个实体。每一个进程都有它自己的地址空间;第二,进程是一个“执行中的程序”。
- 无名管道(pipe)
- 无名管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 速度慢,容量有限,只有父子进程能通讯
- 有名管道 (namedpipe)
- 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号量(semaphore)
- 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 不能传递复杂消息,只能用来同步
- 消息队列(messagequeue)
- 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题 ;信号传递信息较管道多。
- 信号 (signal)
- 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 共享内存(shared memory)
- 共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存。
- 套接字(socket)
- 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。
# 线程间的通信方式
线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
- 锁机制:包括互斥锁、条件变量、读写锁
- 互斥锁提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
- 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 信号量机制(Semaphore)
- 包括无名线程信号量和命名线程信号量。
- 信号机制(Signal)
- 类似进程间的信号处理。线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
# input 如何处理中文输入防抖
使用文本合成系统,当用户使用拼音输入法开始输入汉字时,这个事件 compositionstart 就会被触发,输入结束后触发 compositionend 事件。
input_dom.addEventListener("compositionstart", onCompositionStart);
input_dom.addEventListener("compositionend", onCompositionEnd);
2
# 前端性能优化
前端网站性能优化
- 减少 http 请求数量,浏览器一个域名单次同时发出的请求数量是有限的,每个 http 请求都会经历 tcp 三次握手四次挥手等阶段;css sprites 雪碧图,多张图片合成一张图片,减少 http 请求数,也减少总体积;合并 css、js 文件;路由懒加载 lazyload;
- 控制资源文件加载优先级,css 放在 html 头部,js 放在底部或 body 后面;设置 importance 属性;async、defer 关键字异步加载;
- 静态资源上 cdn,尽量外链 css 和 js,保持代码整洁,利于维护;
- 利用缓存,浏览器缓存;移动端 app 上的 http 缓存只在当前这次 app 存活期间遵循 http 缓存策略,当你的 app 杀死退出后,缓存就会失效。
- 减少重排重绘:基本原理:重排是 DOM 的变化影响到了元素的几何属性(宽和高),浏览器会重新计算元素的几何属性,会使渲染树中受到影响的部分失效,浏览器会验证 DOM 树上的所有其它结点的 visibility 属性,这也是 Reflow 低效的原因。如果 Reflow 的过于频繁,CPU 使用率就会急剧上升。减少 Reflow,如果需要在 DOM 操作时添加样式,尽量使用 增加 class 属性,而不是通过 style 操作样式。
- 减少 dom 操作
- 图标使用 iconfont 替换
- 不使用 css 表达式,会影响效率
- 使用 cdn 网络缓存,加快用户访问速度,减轻源服务器压力,http 缓存只建议加在 cdn 上,应用服务器上不要加缓存,带 hash 的可以加。
- 启用 gzip 压缩
- 伪静态设置
- 合理利用路由懒加载
- 组件库按需加载,使用 es 版本,方便 tree-shaking
- 延迟加载第三方包
- 对资源做 prefetch、preload 预加载;preload 提前加载当前页面需要用到的资源(不执行),prefetch 提前加载下个页面要用到的资源(不执行)。
- 使用多个图片系统域名,使用多个图片系统域名扩大图片的加载请求数量。
- 对域名做 dns 预解析:
<link rel="dns-prefetch" href="//img10.xx.com">,在移动端上有一定效果,因为移动端的 dns 解析比较差。将会用到的域名直接加到 html 的 header 中即可,不需要通过 webpack 去生成。 - 升级 webpack 版本
- 小包替大包,手写替小包,如 dayjs 替换 momentjs
性能优化手段总结:
- 减少首屏资源大小
- 资源混淆压缩
- 资源加上 gzip
- 压缩图片/使用合适的图片类型/大小
- 图片懒加载
- 合理利用路由懒加载
- 组件库按需加载
- 延迟加载第三方包
- 升级 webpack 版本
- 小包替大包,手写替小包
- webpack.externals 配置第三方库不参与打包,而是在 html 中通过 script 标签直接引入公共 CDN
- 减少网络消耗/合理利用网络请求
- 资源合并
- 图片做雪碧图/iconfont/base64
- http 缓存/cdn 缓存
- 资源放 CDN
- 对资源做 preload 和 prefetch
- 使用多个图片系统域名
- 对域名做 dns 预解析
- 优化渲染
- css、js 资源位置
- 避免重绘重排/减少 dom 结构复杂度
- 其他关联系统方面
- 长耗时任务,分析耗时长的接口,后端优化
web-vitals库和 performance 进行结合,分析 LCP:主要内容出现的时间,越短越好;FID:输入延迟的时间,低于 100ms 越好;CLS:页面变化的积累量,低于 0.1 越好
- 使用子域名加载资源
- 使用较近的 CDN 或 dns 预解析
- 使用高性能传输方式或方法,http2,quic,gzip...
- 减少 http 请求的数量,合并公共资源、使用雪碧图、合并代码块、按需加载资源
- 减少传输总量或加快传输速度
- 优化图片的加载展示策略,根据网络状况加载图片、图片格式优化、图片展示位置优化
- 减少 cookie 体积
- 使用更有效的缓存策略,keep-alive,expiration,max-age...
- 使用良好的页面布局
- 合理安排路由策略
- 减少反复操作 dom
- 减少重绘和重排
- 异步加载资源
- 公用 css 类
- 使用 GPU 渲染初始动画和图层的合成
- 高效的 js 代码
- 使用防抖和节流对 UI 进行优化
- 使用 web worker 加载资源
- 减少 301 302
- 试试缓存数据的方法 localStorage/sessionStorage/indexedDB
- 无阻塞加载 js,减少并发下载或请求
- 减少插件中的多语言版本内容
- 减少布局上的颠簸,减少对临近元素的影响
- 减少同时的动画
- 制定弱网精简策略
- 针对设备制定精简策略
- 减少页面图层
- js、css 命名尽量简短
- 减少 js 全局查找
- 减少循环和循环嵌套以减少 js 执行时间
- 减少事件绑定
- 组件提取、样式提取、函数提取
- 按照页面变更频率安排资源
- 减少 iframe
- 注意页面大小,特别是 canvas 的大小和占用内存
# this 指向
fn() < obj.fn() < fn.call(obj) < new fn()四条规则的优先级是递增的:
首先,new 调用的优先级最高,只要有 new 关键字,this 就指向实例本身;接下来如果没有 new 关键字,有 call、apply、bind 函数,那么 this 就指向第一个参数;然后如果没有 new、call、apply、bind,只有 obj.foo()这种点调用方式,this 指向点前面的对象;最后是光杆司令 foo() 这种调用方式,this 指向 window(严格模式下是 undefined)。
es6 中新增了箭头函数,而箭头函数最大的特色就是没有自己的 this、arguments、super、new.target,并且箭头函数没有原型对象 prototype 不能用作构造函数(new 一个箭头函数会报错)。因为没有自己的 this,所以箭头函数中的 this 其实指的是包含函数中的 this。无论是点调用,还是 call 调用,都无法改变箭头函数中的 this。
# 接口防刷
- 网关控制流量洪峰,对在一个时间段内出现流量异常,可以拒绝请求
- 源 ip 请求个数限制。对请求来源的 ip 请求个数做限制
- http 请求头信息校验;(例如 host,User-Agent,Referer)
- 对用户唯一身份 uid 进行限制和校验。例如基本的长度,组合方式,甚至有效性进行判断。或者 uid 具有一定的时效性
- 前后端协议采用二进制方式进行交互或者协议采用签名机制
- 人机验证,验证码,短信验证码,滑动图片形式,12306 形式
- 网络服务商流量清洗(参考 DDoS)
# 路由拦截
# 提高 webpack 打包速度
- 在尽可能少的模块上应用 loader
- Plugin 尽可能精简并可靠
- resolve 参数的合理配置
- 使用 DllPlugin 提高打包速度
- 第三方模块单独打包,生成打包结果
- 使用 library 暴露为全局变量
- 借助 dll 插件来生成 manifest 映射文件,从 dll 文件夹里面拿到打包后的模块(借助 dllReference 插件)就不用重复打包了
- 中间进行了很多分析的过程,最后决定要不要再去分析 node_modules 内容
- 去除冗余引用
- 多进程打包:利用 node 的多进程,利用多个 cpu 进行项目打包(thread-loader,parallel-webpack,happypack)
- 合理使用 SourceMap
- 结合 stats.json 文件分析打包结果;分析 bundle 包,打包后的 bundle 文件生成一个分析文件:
"analyse": "webpack --config ./webpack.config.js --profile --json>states.json" - webpack-analyzer
- 开发环境无用插件需要剔除
# 相关 webpack 插件和 loader 等
四步:分析打包速度,分析打包体积,优化打包速度,优化打包体积。
- 进行优化的第一步需要知道我们的构建到底慢在那里。通过
speed-measure-webpack-plugin测量你的 webpack 构建期间各个阶段花费的时间。使用插件的 wrap()方法将 webpack 配置 module.exports 包起来,打包完成后控制台会输出各个 loader 的打包耗时,可根据耗时进一步优化打包速度; - 体积分析:1.依赖的第三方模块文件大小;2.业务里面的组件代码大小。安装插件
webpack-bundle-analyzer,打包后可以很清晰直观的看出各个模块的体积占比。 - 代码分割:
CommonsChunkPlugin; - 使用
HashedModuleIdsPlugin来保持模块引用的module_id不变; hard-source-webpack-plugin该插件的作用是为打包后的模块提供缓存,且缓存到本地硬盘上。默认的缓存路径是:node_modules/.cache/hard-source。- 使用高版本的 webpack 和 node.js,优化一下代码语法:
for of 替代 forEachMap和Set 替代Objectincludes 替代 indexOf()默认使用更快的md4 hash算法 替代 md5算法,md4较md5速度更快webpack AST 可以直接从loader传递给AST,从而减少解析时间使用字符串方法替代正则表达式
- 多进程/多实例构建(资源并行解析):在 webpack 构建过程中,我们需要使用 Loader 对 js,css,图片,字体等文件做转换操作,并且转换的文件数据量也是非常大的,且这些转换操作不能并发处理文件,而是需要一个个文件进行处理,我们需要的是将这部分任务分解到多个子进程中去并行处理,子进程处理完成后把结果发送到主进程中,从而减少总的构建时间。
- thread-loader(官方推出)
- parallel-webpack
- HappyPack
- 多进程/多实例进行代码压缩(并行压缩):在代码构建完成之后输出之前有个代码压缩阶段,这个阶段也可以进行并行压缩来达到优化构建速度的目的。
webpack-parallel-uglify-pluginuglifyjs-webpack-pluginterser-webpack-plugin(webpack4.0 推荐使用,支持压缩 es6 代码)
- 通过分包提升打包速度:可以使用
html-webpack-externals-plugin分离基础包,分离之后以 CDN 的方式引入所需要的资源文件,缺点就是一个基础库必须指定一个 CDN,实际项目开发中可能会引用到多个基础库,还有一些业务包,这样会打出很多个 script 标签。 - 进一步分包,采用预编译资源模块:采用 webpack 官方内置的插件
DLLPlugin进行分包,DLLPlugin可以将项目中涉及到的例如 react、react-router 等组件和框架库打包成一个文件,同时生成manifest.json文件。manifest.json是对分离出来的包进行一个描述,实际项目就可以引用manifest.json,引用之后就会关联DLLPlugin分离出来的包,这个文件是用来让DLLReferencePlugin映射到相关的依赖上去。 - 通过缓存提升二次打包速度:
babel-loader开启缓存:cacheDirectory=trueterser-webpack-plugin开启缓存:new TerserPlugin({cache: true,})- 使用
cache-loader或者hard-source-webpack-plugin
- 打包体积优化
- 图片压缩:使用 Node 库的 imagemin,配置
image-webpack-loader对图片优化,改插件构建时会识别图片资源,对图片资源进行优化,借助 pngquant(一款 PNG 的压缩器)压缩图片 - 擦除无用到的 css:插件
purgecss-webpack-plugin - 动态 Polyfill:由于 Polyfill 是非必须的,对一些不支持 es6 新语法的浏览器才需要加载 polyfill,为了百分之 3.几的用户让所有用户去加载 Polyfill 是很没有必要的;我们可以通过 polyfill-service,只给用户返回需要的 polyfill。每次用户打开一个页面,浏览器端会请求 polyfill-service,polyfill-service 会识别用户 User Agent,下发不同的 polyfill。如何使用动态 Polyfill service,通过官方 (opens new window)提供的服务,自建 polyfill 服务。
- 图片压缩:使用 Node 库的 imagemin,配置
# ES6 继承
参考「ES5/ES6 的继承除了写法以外还有什么区别」
# 路由跳转
history.replaceState();
# 管道函数
将多个函数按顺序组合起来,使数据依次通过这些函数进行处理。
// 管道函数实现
// 从左向右执行
const pipe =
(...functions) =>
(input) =>
functions.reduce((acc, fn) => fn(acc), input);
// 或者
const pipe =
(...fns) =>
(x) =>
fns.reduce((v, f) => f(v), x);
// 示例函数
const add = (x) => x + 2;
const multiply = (x) => x * 3;
const square = (x) => x * x;
// 使用管道
const process = pipe(add, multiply, square);
console.log(process(2)); // (((2 + 2) * 3) ^ 2) = 144
// 从右向左执行
// 从右向左的函数组合
const compose =
(...functions) =>
(input) =>
functions.reduceRight((acc, fn) => fn(acc), input);
// 示例函数
const add = (x) => x + 2;
const multiply = (x) => x * 3;
const square = (x) => x * x;
// 使用 compose
const process = compose(square, multiply, add);
console.log(process(2)); // (((2 + 2) * 3) ^ 2) = 144
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 如何不指定特定的文件来创建 webworker
用途:打包的时候不希望打出一堆 worker 文件,而希望和主线程代码放在一起的时候,可以把这些 worker 的代码写成字符串,然后通过如下两种方法来生成 worker。
不用特定 js 文件的话,那就需要把 js 代码写成字符串,然后:有两种做法
- Object URL: 是一种特殊的 URL,它表示一个对象,该对象可以作为 URL 的一部分(本地的临时资源)。Object URL 可以用于创建指向 JavaScript 代码的 URL。先用这个字符串创建一个 blob 对象,然后通过 URL.createObjectURL(blob)创建一个 URL,然后通过 new Worker(URL)创建一个 worker 对象。
- Data URL: 有固定格式:
data:application/javascript;utf8,${sourceCode}(直接把资源写到字符串里了),然后通过 new Worker(dataUrl)创建一个 worker 对象。
// 1. Object URL
// 定义 Worker 的功能
const workerCode = `
self.onmessage = function(e) {
const result = e.data * 2; // 例如,将收到的数据乘以 2
self.postMessage(result); // 将结果发送回主线程
};
`;
// 创建一个 Blob 对象
const blob = new Blob([workerCode], { type: "application/javascript" });
// 创建对象 URL
const workerBlobURL = URL.createObjectURL(blob);
// 创建 Worker 实例
const worker1 = new Worker(workerBlobURL);
// 监听 Worker 发送的消息
worker1.onmessage = function (e) {
console.log("Worker 发送的结果:", e.data);
};
// 向 Worker 发送数据
worker1.postMessage(10); // 发送数字 10
// 2. Data URL
const dataUrl = `data:application/javascript;utf8,${workerCode}`;
const worker2 = new Worker(dataUrl);
// 监听 Worker 发送的消息
worker2.onmessage = function (e) {
console.log("Worker 发送的结果:", e.data);
};
// 向 Worker 发送数据
worker2.postMessage(20); // 发送数字 20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 作用域链
参考「V8」
# keep-alive 使用
- keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,避免重新渲染
- 一般结合路由和动态组件一起使用,用于缓存组件;
- 提供 include 和 exclude 属性,两者都支持字符串或正则表达式, include 表示只有名称匹配的组件会被缓存,exclude 表示任何名称匹配的组件都不会被缓存 ,其中 exclude 的优先级比 include 高;
- 对应两个钩子函数 activated 和 deactivated ,当组件被激活时,触发钩子函数 activated,当组件被移除时,触发钩子函数 deactivated。
# keep-alive 原理
Vue 的渲染是从 render 阶段开始的,但 keep-alive 的渲染是在 patch 阶段,这是构建组件树(虚拟 DOM 树),并将 VNode 转换成真正 DOM 节点的过程。
- 原理:源码就类似于一个 SFC 的 script 部分
- 在 created 生命周期时,初始化了 cache 缓存对象和 keys 对象,cache 用于缓存虚拟 dom,keys 主要用于保存 VNode 对应的键集合
- 在 destroyed 生命周期时,删除缓存 VNode 还要对应执行组件实例的 destory 钩子函数。
- 在 mounted 这个钩子中对 include 和 exclude 参数进行监听,然后实时地更新(删除)this.cache 对象数据。pruneCache 函数的核心也是去调用 pruneCacheEntry。
所以 keep-alive 的原理可以分成以下几步:
- 获取 keep-alive 包裹着的第一个子组件对象及其组件名;
- 根据设定的 include/exclude(如果有)进行条件匹配,决定是否缓存。不匹配,直接返回组件实例;
- 根据组件 ID 和 tag 生成缓存 Key,并在缓存对象中查找是否已缓存过该组件实例。如果存在,直接取出缓存值并更新该 key 在 this.keys 中的位置(更新 key 的位置是实现 LRU 置换策略的关键);
- 如果不匹配,在 this.cache 对象中存储该组件实例并保存 key 值,之后检查缓存的实例 数量是否超过 max 的设置值,超过则根据 LRU 置换策略删除最近最久未使用的实例(即是下标为 0 的那个 key);
- 最后组件实例的 keepAlive 属性设置为 true,这个在渲染和执行被包裹组件的钩子函数会用到。
- render 过程:
- 第一步:获取 keep-alive 包裹着的第一个子组件对象及其组件名;
- 第二步:根据设定的黑白名单(如果有)进行条件匹配,决定是否缓存。不匹配,直接返回组件实例(VNode),否则执行第三步;
- 第三步:根据组件 ID 和 tag 生成缓存 Key,并在缓存对象中查找是否已缓存过该组件实例。如果存在,直接取出缓存值并更新该 key 在 this.keys 中的位置(更新 key 的位置是实现 LRU 置换策略的关键),否则执行第四步;
- 第四步:在 this.cache 对象中存储该组件实例并保存 key 值,之后检查缓存的实例数量是否超过 max 的设置值,超过则根据 LRU 置换策略删除最近最久未使用的实例(即是下标为 0 的那个 key)。
- 第五步:最后并且很重要,将该组件实例的 keepAlive 属性值设置为 true。
- 从 render 到 patch 的过程:
- Vue 在渲染的时候先调用原型上的_render 函数将组件对象转化为一个 VNode 实例;而_render 是通过调用 createElement 和 createEmptyVNode 两个函数进行转化;
- createElement 的转化过程会根据不同的情形选择 new VNode 或者调用 createComponent 函数做 VNode 实例化;
- 完成 VNode 实例化后,这时候 Vue 调用原型上的_update 函数把 VNode 渲染为真实 DOM,这个过程又是通过调用patch函数完成的(这就是 pacth 阶段了)
keep-alive 组件的渲染:
Q:用过 keep-alive 都知道,它不会生成真正的 DOM 节点,这是怎么做到的?
A:Vue 在初始化生命周期的时候,为组件实例建立父子关系会根据 abstract 属性决定是否忽略某个组件。在 keep-alive 中,设置了 abstract: true,那 Vue 就会跳过该组件实例。最后构建的组件树中就不会包含 keep-alive 组件,那么由组件树渲染成的 DOM 树自然也不会有 keep-alive 相关的节点了。
Q:keep-alive 包裹的组件是如何使用缓存的?
A:在 patch 阶段,会执行 createComponent 函数:
- 在首次加载被包裹组件时,由 keep-alive.js 中的 render 函数可知,vnode.componentInstance 的值是 undefined,keepAlive 的值是 true,因为 keep-alive 组件作为父组件,它的 render 函数会先于被包裹组件执行;那么就只执行到 i(vnode, false /_ hydrating _/),后面的逻辑不再执行;
- 再次访问被包裹组件时,vnode.componentInstance 的值就是已经缓存的组件实例,那么会执行 insert(parentElm, vnode.elm, refElm)逻辑,这样就直接把上一次的 DOM 插入到了父元素中。
Q:一般的组件,每一次加载都会有完整的生命周期,即生命周期里面对应的钩子函数都会被触发,为什么被 keep-alive 包裹的组件却不是呢?
A:被缓存的组件实例会为其设置 keepAlive = true,而在初始化组件钩子函数中:从 componentVNodeHooks()函数中可以看出,当 vnode.componentInstance 和 keepAlive 同时为 truly 值时,不再进入$mount 过程,那 mounted 之前的所有钩子函数(beforeCreate、created、mounted)都不再执行。
在 patch 的阶段,最后会执行 invokeInsertHook 函数,而这个函数就是去调用组件实例(VNode)自身的 insert 钩子,在这个 insert 钩子里面,调用了 activateChildComponent 函数递归地去执行所有子组件的 activated 钩子函数。相反地,deactivated 钩子函数也是一样的原理,在组件实例(VNode)的 destroy 钩子函数中调用 deactivateChildComponent 函数。
# keep-alive 层级较深的时候怎么处理?
keep-alive 组件对第三级及以上级的路由页面缓存失效。 方案 1、直接将路由扁平化配置,都放在一级或二级路由中 方案 2、再一层缓存组件用来过渡,并将其 name 配置到 include 中
- 每一层的
<router-view>/组件都包裹一层keep-alive就好了?- 菜单多层级嵌套底下的子组件是不会缓存下来的,这个时候我们就要继续往下给下面的层级继续加上
keep-alive; - 同时在
keep-alive的 include 中绑定一个数组 cachesViewList,数组里面必须把它父级的 name 都放进去。
- 菜单多层级嵌套底下的子组件是不会缓存下来的,这个时候我们就要继续往下给下面的层级继续加上
- 把嵌套的
<router-view>拍平,也就是在路由守卫router.afterEach中添加一个将无用的 layout 布局过消除的方法- 因为
import()异步懒加载,第一次获取不到element.components.default.name,所以不能再beforeEach做,不然第一次访问的界面不缓存第二次才会缓存 afterEach就不一样了,这时候可以获取到element.components.default.name了
- 因为
# 缓存后如何获取数据
- beforeRouteEnter:每次组件渲染的时候,都会执行 beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
2
3
4
5
6
7
- activated:在 keep-alive 缓存的组件被激活的时候,都会执行 actived 钩子
activated(){
this.getData() // 获取数据
},
2
3
# 购物车提交订单数据怎么传
- 商品添加至购物车是不需要登录的,但是需要把 skuId 和数量传给后端,查询是否有库存,然后返回给前端,并把购物车信息存在 cookie (或者 sessionStorage) 里。
- 选择购物车内的商品购买,提交订单,这时候需要用户登录了。
- 用户登录后获取用户 cookie (或者 sessionStorage)内购物车信息,以及登录信息,更新数据库或 redis 中的购物车表(购物车表,一个 skuId 对应购物车一条记录)。
- 用户勾选购物车内商品,生成预览订单(重新获取商品的最新情况比如库存、商品价格等),具体金额由后端计算并返回给前端(前端计算的值仅供参考)。
- 提交并生成订单唤起支付组件或跳到支付页面,然后删除购物车已购买的商品,预减库存,同步更新 cookie (或者 sessionStorage)内购物车信息。
一般会先从购物车或者商品详情页到确认订单页面。根据确认订单页面的数据格式从购物车组织数据(通常最后是搞成一个 json 对象或者跟后端约定拼成字符串),然后存在 localstorage 里面(做的都是移动端),然后直接跳页面,去确认订单页面遍历渲染那个数据对象就好了。前端这些只是给用户看的,后台在付钱的时候还会再算一遍订单金额,再拆单的。所以就算用户改了支付信息,他还是要付那些钱的。
例:淘宝购物车 post 方法更新购物车的 payload:
{
"_input_charset": "utf-8",
"tk": "f88fe5116a335",
"_tb_token_": "f88fe5116a335",
"data": [
{
"shopId": "s_3910391259",
"comboId": 0,
"shopActId": 0,
"cart": [
{
"quantity": 43,
"cartId": "4117652227290",
"skuId": "4811854276366",
"itemId": "644712582517"
}
],
"operate": ["4117652227290"],
"type": "update"
}
],
"shop_id": 0,
"t": 1656004343910,
"type": "update",
"ct": "e5798e786c8a9627ee23ada7a462673c",
"page": 1,
"_thwlang": "zh_CN"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# js 精度丢失
- 原因:在 JavaScript 中,现在主流的数值类型是 Number,而 Number 采用的是 IEEE754 规范中 64 位双精度浮点数编码:
- 符号位 S:第 1 位是正负数符号位(sign),0 代表正数,1 代表负数
- 指数位 E:中间的 11 位存储指数(exponent),用来表示次方数,可以为正负数。在双精度浮点数中,指数的固定偏移量为 1023
- 尾数位 M:最后的 52 位是尾数(mantissa),超出的部分自动进一舍零
因为存储时有位数限制(64 位),并且某些十进制的浮点数在转换为二进制数时会出现无限循环,会造成二进制的舍入操作(0 舍 1 入),当再转换为十进制时就造成了计算误差。
理论上用有限的空间来存储无限的小数是不可能保证精确的,但我们可以处理一下得到我们期望的结果。
- 保留需要的小数位数,
toFixed(保留位数):不够精确,有时 5 不会进位; - 字符串模拟:基本原理是将浮点数表示为整数进行计算,然后再转换回浮点数。
bignumber.js第三方库: 解决大数的问题。原理是把所有数字当作字符串,重新实现了计算逻辑,缺点是性能比原生差很多。0.10000000000000000555.toPrecision(16);// 原生 API,做精度运算,超过的精度会自动做凑整处理,返回字符串。使用 toPrecision 凑整并 parseFloat 转成数字后再显示。math.js、BigDecimal.js、big.js、decimal.js(据说计算基金净值比较快)- 最后,建议所有对运算精度要求极高的业务场景都放到后端去运算,切记。
- 对于运算类操作,如
+-*/,就不能使用 toPrecision 了。正确的做法是把小数转成整数后再运算,也是有上限的,对于非常大的浮点数,转换为整数可能会超出 JavaScript 的安全整数范围(Number.MAX_SAFE_INTEGER),如果小数位不确定这个方法也可能会有误差。以加法为例:
- 保留需要的小数位数,
/**
* 精确加法
*/
function add(num1, num2) {
const num1Digits = (num1.toString().split(".")[1] || "").length;
const num2Digits = (num2.toString().split(".")[1] || "").length;
const baseNum = Math.pow(10, Math.max(num1Digits, num2Digits));
return (num1 * baseNum + num2 * baseNum) / baseNum;
}
2
3
4
5
6
7
8
9
number.toPrecision(precision);,precision:一个介于 1 到 100 之间的整数,表示有效数字的位数。返回一个表示指定精度的数字字符串。可以返回科学计数法表示(如 "1.2e+2")。
let num = 123.456;
console.log(num.toPrecision(2)); // "1.2e+2"(科学计数法)
console.log(num.toPrecision(4)); // "123.5"
console.log(num.toPrecision(5)); // "123.46"
console.log((123.455).toPrecision(5)); // "123.45"
console.log(num.toPrecision(6)); // "123.456"
console.log(num.toPrecision(1)); // "1e+2"
2
3
4
5
6
7
8
# 运算符优先级

# 数组扁平化
即把数组从多维的展成一维的。大概有如下几种方法:
- 使用
Array.prototype.flat():arr.flat(Infinity)使用 Infinity 可以展开任意深度的嵌套数组。 - 递归方法,对于大型数组或深层嵌套,可能导致栈溢出。
- 使用 reduce 方法
- 使用扩展运算符
代码示例:
const arr = [1, [2, [3, 4], 5], 6, [7, 8]];
console.log(arr.flat(Infinity)); // [1, 2, 3, 4, 5, 6, 7, 8]
function flattenArray(arr) {
let result = [];
for (let i = 0; i < arr.length; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flattenArray(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
const arr = [1, [2, [3, 4], 5], 6, [7, 8]];
console.log(flattenArray(arr)); // [1, 2, 3, 4, 5, 6, 7, 8]
function flattenArray(arr) {
return arr.reduce((acc, val) => (Array.isArray(val) ? acc.concat(flattenArray(val)) : acc.concat(val)), []);
}
const arr = [1, [2, [3, 4], 5], 6, [7, 8]];
console.log(flattenArray(arr)); // [1, 2, 3, 4, 5, 6, 7, 8]
function flattenArray(arr) {
while (arr.some((item) => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
const arr = [1, [2, [3, 4], 5], 6, [7, 8]];
console.log(flattenArray(arr)); // [1, 2, 3, 4, 5, 6, 7, 8]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# jsBridge 通信失败怎么处理
- 错误检测和日志记录:首先,实现一个全面的错误检测和日志记录机制
- 重试机制:对于一些非关键操作,可以实现自动重试机制
- 降级策略:当 JSBridge 完全不可用时,实现降级策略
- 版本检查:确保 Web 端和 App 端的 JSBridge 版本兼容
- 超时处理:为 JSBridge 调用添加超时处理
- 健康检查/网络检查:定期进行 JSBridge 健康检查
- 用户反馈:当遇到持续的 JSBridge 问题时,提供用户反馈机制
# h5 怎么调用 native 的方法
# v-if 和 v-show 的区别
- v-if:条件判断,当条件为 true 时,渲染组件;当条件为 false 时,组件根节点会被销毁,不再渲染。v-show:条件展示,当条件为 true 时,渲染组件;当条件为 false 时,组件根节点仍然存在,只是
display:none。 - v-if 的开销较大,因为它涉及到组件的销毁和重建;v-show 的开销较小,因为它只是简单地切换 CSS 属性。
- v-if 有更高的切换开销,因为它需要同时把旧的组件实例销毁(回收内存)和新的组件实例创建(渲染);v-show 有更高的初始渲染开销,因为它需要初始渲染时就渲染组件,没有切换过程。
- v-if 适用于运行时条件,v-show 适用于初始渲染条件。
- v-if 惰性渲染,性能开销大,适合条件切换较少的场景。v-show 通过样式控制显示,性能开销小,适合频繁切换的场景。
- v-if:会触发组件的生命周期钩子(如 created、mounted 等)。v-show:不会触发组件的生命周期钩子。
- v-if:可以和
v-else、v-else-if配合使用。v-show:不能和 v-else 等指令配合使用。 - v-show: 条件切换频率较高。页面初次加载时,内容需要渲染出来,但可以通过样式快速切换来控制显示。
- v-if: 如果涉及敏感信息或需要严格控制渲染。条件切换较少。页面初次加载时,需要根据条件决定是否渲染内容,条件为 true 时才渲染。隐藏的内容较多,或者需要动态销毁和重新创建的场景。
| 特性 | v-if | v-show |
|---|---|---|
| 机制 | 添加或移除 DOM 元素 | 修改元素的 display 样式 |
| 初始渲染 | 条件为 true 时才渲染 | 无论条件如何,都会渲染一次 |
| 切换性能 | 切换成本高,适合条件变化不频繁 | 切换成本低,适合频繁显示/隐藏 |
| DOM 占用 | 条件为 false 时,不存在于 DOM | 始终存在于 DOM 中 |
# 合成事件和原生事件
- 原生事件是浏览器提供的 DOM 事件,直接绑定在真实的 DOM 节点上。例如,常见的原生事件有 click、mousemove、keydown 等。这些事件是由浏览器引擎直接触发和管理的。
- 合成事件是 React 提供的一种跨浏览器的事件封装。React 的合成事件系统是为了提供一致的接口,保证在不同浏览器中具有相同的行为,并且能够更高效地管理事件。React 中的事件处理函数接收到的事件对象是 SyntheticEvent,而不是原生的 DOM 事件对象。
- 合成事件:通过事件委托和池化机制提高性能,减少内存分配和垃圾回收。原生事件:直接绑定在 DOM 上,无法享受 React 的优化。
- 合成事件:默认绑定在组件的根节点,通过事件委托机制进行处理。原生事件:可以直接绑定在具体的 DOM 节点上。
合成事件的特点:
- 跨浏览器兼容性:合成事件屏蔽了浏览器之间的兼容性问题,提供了一致的 API。
- 事件池化:React 对合成事件进行了池化,这意味着在事件回调函数中不能异步访问事件对象,因为事件对象会被重用以提高性能。在异步操作中,需要调用事件对象的 persist() 方法来保持事件的引用。
- 与原生事件的交互:合成事件在事件冒泡阶段被处理,通常绑定在组件的根节点上,而不是直接绑定在 DOM 节点上。
import React from "react";
function Example() {
// 合成事件
const handleClick = (e) => {
console.log("合成事件:", e);
console.log("合成事件类型:", e.type);
// 保留事件对象以供异步使用
e.persist();
setTimeout(() => {
console.log("异步访问事件对象:", e.type);
}, 1000);
};
// 原生事件
const divRef = React.useRef(null);
React.useEffect(() => {
const handleNativeClick = (e) => {
console.log("原生事件:", e);
};
const currentDiv = divRef.current;
currentDiv.addEventListener("click", handleNativeClick);
// 清除原生事件监听器
return () => {
currentDiv.removeEventListener("click", handleNativeClick);
};
}, []);
return (
<div ref={divRef} onClick={handleClick}>
点击我
</div>
);
}
export default Example;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# React 中定义一个变量,不使用 state 怎么更新它?
在 React 中,如果一个变量的变化不需要触发组件重新渲染,可以使用 useRef 来保持其值。useRef 可以在组件的生命周期内保持不变且不会引起重渲染。
import React, { useRef } from "react";
function ExampleComponent() {
const countRef = useRef(0);
const increment = () => {
countRef.current += 1;
console.log(countRef.current);
};
return <button onClick={increment}>Increase</button>;
}
2
3
4
5
6
7
8
9
10
11
12
# 前端如何优雅通知用户刷新页面
这里说的是用户不会主动刷新页面的情况,比如代码更新了,需要主动弹窗等方式通知用户刷新页面。
- 前端起一个定时器 setInterval 轮询后端服务器,对比 etag 是否变化,如果变化,则刷新页面。
- 每次上线,后端加一下自定义响应字段
add_header X-App-Version "1.0.0",然后前端每次请求都会带上,如果某次带的和返回的不一致就是有更新,提示用户刷新。 - websocket 或者 EventSource(SSE),服务端推送版本变化情况,前端监听结果并根据结果刷新页面。
- 使用 Service Worker,监听更新事件,当检测到新版本时,提示用户刷新页面。
# 实现一个支持链式调用的函数
- 利用 Proxy 的特性,拦截函数调用,返回一个新的函数,该函数在调用时会更新变量的值。
function chain(value) {
const handler = {
get: function (obj, prop) {
if (prop === "end") {
return obj.value;
}
if (typeof window[prop] === "function") {
obj.value = window[prop](obj.value);
return proxy;
}
return obj[prop];
},
};
const proxy = new Proxy({ value }, handler);
return proxy;
}
function plusOne(a) {
return a + 1;
}
function double(a) {
return a * 2;
}
function minusOne(a) {
return a - 1;
}
console.log(chain(1).plusOne.double.minusOne.end); // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 动态执行函数
eval(str)-> 同步代码,作用域是局部/函数作用域setTimeout(str, 0)-> 宏任务,需要注意作用域是全局作用域(new Function(arg1, arg2, str))()-> 同步代码<script>标签 -> 在浏览器的 JavaScript 环境中,<script>标签中的代码是在宏任务(macro task)中执行的。script.textContent = str; document.body.appendChils(script);
# 静态属性与动态属性
- 静态属性:
- 静态属性是定义在类或对象的构造函数上,属性名是硬编码,且在编写时就已知,可以通过类名或对象名直接访问。
- 可以直接通过
.点符号访问 - 不能使用数字、变量作为属性名
- 动态属性:
- 可以通过方括号
[]访问但不能通过.点符号访问 - 可以在运行时计算得出,可以使用数字、变量、字符串字面量、表达式作为属性名
- 可以通过方括号
# 函数的 name 是不可被修改的
# ==/===/Object.is()的区别
==会进行隐式类型转换。===/Object.is()不会进行类型转换,===会比较值和类型,Object.is()也会比较值和类型,但NaN === NaN为 false,而Object.is(NaN, NaN)为 true。+0===-0是 true,而Object.is(+0, -0)为 false。- ==相等比较:如果一个操作数是对象,另一个操作数是字符串或者数字,会首先调用对象的 valueOf 方法,将对象转化为基本类型,在进行比较。当 valueOf 返回的不是基本类型的时候,才会调用 toString 方法。
# 页面多图片加载优化
# 移动端 h5 适配问题
# 二叉搜索树
# 白屏原因&优化
# 白屏时间计算
# Git hotfix
# npm i/npm start/npm run build 区别
# webpack 热加载 hmr 原理
Webpack HMR 特性的原理并不复杂,核心流程:
- 使用 webpack-dev-server (后面简称 WDS)托管静态资源,同时以 Runtime 方式注入 HMR 客户端代码
- 浏览器加载页面后,与 WDS 建立 WebSocket 连接
- Webpack 监听到文件变化后,增量构建发生变更的模块,并通过 WebSocket 发送 hash 事件
- 浏览器接收到 hash 事件后,请求 manifest 资源文件,确认增量变更范围
- 浏览器加载发生变更的增量模块
- Webpack 运行时触发变更模块的 module.hot.accept 回调,执行代码变更逻辑
- done
Webpack 的 HMR 特性有两个重点,一是监听文件变化并通过 WebSocket 发送变更消息;二是需要客户端提供配合,通过 module.hot.accept 接口明确告知 Webpack 如何执行代码替换。
# vue diff 和 react diff
| 特性 | React Diff | Vue Diff |
|---|---|---|
| 基本策略 | 同层比较 + key 优化 | 同层比较 + 双端比较 |
| 列表 Diff | 依赖唯一 key,逐一对比 | 双端比较,按头尾指针寻找最优解 |
| 跨层级操作 | 不支持,跨层级直接删除新增 | 同样不支持,直接删除新增 |
| 性能 | 列表更新性能依赖于 key 是否合理 | 列表更新性能较高,适合头尾频繁插入删除 |
| 复杂度 | O(n) | O(n) |
原理和区别:
虚拟 DOM 树同层比较:只比较虚拟 DOM 的同一层级,不会跨层级比较,如果节点类型相同(如
<div>对比<div>),则继续对比属性和递归对比子节点。如果类型不同,则直接销毁旧节点,创建新节点。React 列表的比较:使用 key 进行优化,避免出现全量更新。
- 如果所有节点都有唯一的 key,React 可以快速找到对应的节点,按 key 匹配更新。即使节点顺序发生变化,也只更新必要部分。
- 如果没有 key 或 key 不唯一,React 会按默认顺序逐一对比,这在插入或删除节点时可能导致性能下降。
Vue 列表的比较:使用了一种高效的 双端比较算法。它通过四个指针,分别指向新旧列表的头尾节点,
- 从新旧列表的头部开始比较,如果相同则复用,更新内容,指针向后移动。newStart++,oldStart++。否则,进入下一步。
- 从新旧列表的尾部开始比较,如果相同则复用,更新内容,指针向前移动。newEnd--,oldEnd--。否则,进入下一步。
- 比较新列表的起始节点与旧列表的结束节点,如果相同则复用,更新内容,将旧节点移动到 newStart 的位置(DOM 操作),移动指针:newStart++,oldEnd--。否则,进入下一步。
- 比较新列表的结束节点与旧列表的起始节点,如果相同则复用,更新内容,将旧节点移动到 newEnd 的位置(DOM 操作),移动指针:newEnd--,oldStart++。否则,进入下一步。
- 如果头尾无法匹配即以上 4 步均未找到相同节点,则尝试查找旧节点中能复用的节点(通过 key 查找新节点在旧列表中的位置)-遍历旧列表,查找 newStart 节点是否存在。如果找到:复用旧节点,更新内容(如有变化)。将旧节点移动到 newStart 的位置(DOM 操作)。如果未找到:创建新节点并插入到 newStart 的位置(DOM 操作)。移动指针:newStart++。
- 处理剩余节点,如果旧列表遍历完毕,但新列表仍有剩余节点:创建新节点并插入到对应位置(DOM 操作)。如果新列表遍历完毕,但旧列表仍有剩余节点:删除旧节点(DOM 操作)。
总结:
- React 的 diff 算法更侧重于简单规则和 key 的使用,通过假设更新操作是局部的来优化性能。
- Vue 的 diff 算法使用了双端比较,更适合频繁插入、删除的场景,进一步提升了列表的更新效率。
- 两者的核心思想是相似的,都是为了实现高效的视图更新,但实现细节和场景优化各有侧重。
# vue 指令
# 扁平数据结构转 Tree
const arr = [
{ id: 1, name: "部门1", pid: 0 },
{ id: 2, name: "部门2", pid: 1 },
{ id: 3, name: "部门3", pid: 1 },
{ id: 4, name: "部门4", pid: 3 },
{ id: 5, name: "部门5", pid: 4 },
];
// 转为tree
[
{
id: 1,
name: "部门1",
pid: 0,
children: [
{
id: 2,
name: "部门2",
pid: 1,
children: [],
},
{
id: 3,
name: "部门3",
pid: 1,
children: [
// 结果 ,,,
],
},
],
},
];
// 1
/**
* 递归查找,获取children
*/
const getChildren = (data, result, pid) => {
for (const item of data) {
if (item.pid === pid) {
const newItem = { ...item, children: [] };
result.push(newItem);
getChildren(data, newItem.children, item.id);
}
}
};
/**
* 转换方法
*/
const arrayToTree = (data, pid) => {
const result = [];
getChildren(data, result, pid);
return result;
};
// 2
function arrayToTree(items) {
const result = []; // 存放结果集
const itemMap = {}; //
// 先转成map存储
for (const item of items) {
itemMap[item.id] = { ...item, children: [] };
}
for (const item of items) {
const { id, pid } = item;
const treeItem = itemMap[id];
if (pid === 0) {
// root
result.push(treeItem);
} else {
if (!itemMap[pid]) {
itemMap[pid] = {
children: [],
};
}
itemMap[pid].children.push(treeItem);
}
}
return result;
}
// 3 性能最优
function arrayToTree(items, rootId) {
const result = []; // 存放结果集
const itemMap = {}; //
for (const item of items) {
const id = item.id;
const pid = item.pid;
if (!itemMap[id]) {
itemMap[id] = {
children: [],
};
}
itemMap[id] = {
...item,
children: itemMap[id]["children"],
};
const treeItem = itemMap[id];
if (pid === rootId) {
result.push(treeItem);
} else {
if (!itemMap[pid]) {
itemMap[pid] = {
children: [],
};
}
itemMap[pid].children.push(treeItem);
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
# JavaScript 中 (0, function)(param) 是什么?
- 通常用于改变函数调用时的上下文 this 的指向,或者用于间接调用函数。确保函数调用时,this 指向的是全局上下文对象(严格模式下是 undefined),而不是当前作用域。可用于:模块化代码、避免副作用、解绑对象方法。
- 逗号操作符: 对它的每个操数求值(从左到右),并返回最后一个操作数的值。
- eval 执行的代码环境上下文,通常是局部上下文。直接调用,使用本地作用域。间接调用,使用全局作用域。
function test() {
var x = 2,
y = 4;
console.log(eval("x + y")); // 直接调用,使用本地作用域,结果是 6
var geval = eval; // 等价于在全局作用域调用
console.log(geval("x + y")); // 间接调用,使用全局作用域,throws ReferenceError 因为`x`未定义
}
// 解绑对象方法
const obj = {
value: "Hello",
logValue() {
console.log(this.value);
},
};
// 直接调用,this 指向 obj
obj.logValue(); // 输出: Hello
// 使用 (0, function) 解绑 this
const logValue = (0, obj.logValue);
logValue(); // 输出: undefined(严格模式)或 window.value(非严格模式)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
(0,eval)属于间接调用,使用的是 全局作用域,this 指向的是全局上下文。- 为什么不用 call / apply 指定全局上下文 window ? 是为预防 call / apply 被篡改后,导致程序运行异常。
- 为什么逗号操作符用 0 ? 其实,用其他数字或者字符串也是没问题的。至于为什么用 (0, function) ? 可以说是业界的默认规则。如果硬要说个为什么,可能是 0 在二进制的物理存储方式上,占用的空间较小。
# 并发请求
// 给定一个待请求的url数组,和允许同时发出的最大请求数,写一个函数fetch并发请求,要求最大并发数为maxNum,并且尽可能快的完成所有请求
const urls = [
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
"https://jsonplaceholder.typicode.com/posts/4",
"https://jsonplaceholder.typicode.com/posts/5",
"https://jsonplaceholder.typicode.com/posts/6",
"https://jsonplaceholder.typicode.com/posts/7",
"https://jsonplaceholder.typicode.com/posts/8",
"https://jsonplaceholder.typicode.com/posts/9",
"https://jsonplaceholder.typicode.com/posts/10",
];
function fetchUrls(urls, maxNum) {
return new Promise((resolve) => {
if (urls.length === 0) {
resolve([]);
return;
}
const results = new Array(urls.length);
let count = 0;
let index = 0;
async function request() {
if (index >= urls.length) {
return;
}
const curIndex = index++;
const url = urls[curIndex];
try {
const res = await fetch(url);
results[curIndex] = await res.json(); // Assuming you want the JSON response
} catch (e) {
results[curIndex] = e;
} finally {
count++;
if (count === urls.length) {
resolve(results);
} else {
request(); // Start the next request
}
}
}
const times = Math.min(maxNum, urls.length);
// 最开始先同时发出times个请求,然后每个请求结束后在finally中判断count也就是一共已经发出了多少个请求,如果还有请求没发出,那就继续调用request,否则就把results返回。
for (let i = 0; i < times; i++) {
request();
}
});
}
fetchUrls(urls, 3).then((results) => {
console.log(results);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# Composition API 有哪些
- setup 函数:是 Composition API 的入口点,用于定义组件的响应式状态、计算属性、方法等,在组件创建之前执行,可以返回一个对象,对象中的属性和方法可以在模板中直接使用。
- ref 和 reactive:用于定义响应式数据,ref 用于定义单个基本数据类型的响应式数据,reactive 用于定义对象或数组的响应式数据。
- computed:用于定义计算属性,计算属性会根据依赖的数据自动更新,且会缓存计算结果。
- watch 和 watchEffect:用于监听数据的变化,watch 用于监听指定的数据,watchEffect 用于监听数据的变化,不需要指定监听的数据。
- 生命周期钩子:使用 onMounted、onUpdated、onUnmounted 等函数来定义组件的生命周期钩子。用于在组件的不同生命周期阶段执行代码。
# Vue3 中父子组件通信的方式
props:父组件通过 props 向子组件传递数据。$emit事件:子组件通过 $emit 触发父组件的事件,可以向父组件传递数据。provide/inject:父组件通过 provide 提供数据,子组件通过 inject 注入数据。适用于跨多层的组件之间的通信。- vuex/Pinia:状态管理库,适用于大/中小型应用的状态管理,集中管理应用的状态,使得状态的变化可预测。
- EventBus:通过事件总线实现父子组件通信,适用于简单的应用场景。
$attrs/$listeners:适用于透传属性和事件,将父组件的属性和事件透传给子组件。v-model:用于实现双向绑定,父组件通过 v-model 绑定数据,子组件通过 emit 触发 input 事件。v-model是语法糖,等价于:value和@input两个属性。- 子组件通过 emit 触发
update:modelValue事件,父组件通过 v-model 绑定数据。modelValue是v-model的默认 prop 名称,update:modelValue是v-model的默认事件名称。 <input :value="props.modelValue" @input="emit('update:modelValue', $event.target.value)" />。- 可以传递多个参数:
<Child v-model:param1="param1" v-model:param2="param2" />。 - 父组件中的监听是通过
v-model自动实现的,监听的属性名即v-model传的参数的名称。
$refs:父组件通过 $refs 获取子组件的实例,从而调用子组件的方法或访问子组件的数据。
# Vue 3 Proxy 响应式系统的优化
- Proxy 使 Vue3 的响应式系统更高效,支持新增属性监听、数组操作拦截等。
- 依赖按需收集:Vue2 在初始化时遍历整个对象,而 Vue3 采用
Lazy Proxy(惰性代理)只有在访问属性时才进行代理,减少性能消耗。 - 自动清理无效依赖:Vue3 采用
WeakMap + Set进行依赖存储,避免内存泄漏,Vue2 需要手动管理依赖删除。 - 只更新受影响的组件 Vue3 的
trigger()机制让每个组件只更新它所依赖的部分,避免 Vue2 中全局重新计算的问题。
# 消除异步的传染性
及如果一个函数调用了另一个异步的函数,那么这个函数也会变成异步的。
比如:fetch 是异步的函数,那么可以把 fetch 改成同步的函数,这样就可以消除异步的传染性。
例如:自定义 myFetch 函数,在执行 fetch 时先查看缓存,如有缓存则返回缓存,否则先抛出一个 Error 中断执行,然后在 fetch 成功后抛出一个 resolve 设置缓存,重新执行 fetch 或者 main 函数。
React 中的 Suspense 组件也是类似的原理,通过抛出一个 Promise 中断渲染,然后在 Promise resolve 后重新渲染。渲染两次组件。
function run(func) {
// 1. 保存旧的fetch函数
const oldFetch = window.fetch;
// 2. 修改fetch
const cache = {
status: "pending", // 'pending' | 'fulfilled' | 'rejected'
value: null,
};
function myFetch(...args) {
if (cache.status === "fulfilled") {
return cache.value;
} else if (cache.status === "rejected") {
throw cache.value;
}
const promise = oldFetch(...args)
.then((res) => res.json())
.then((res) => {
cache.status = "fulfilled";
cache.value = res;
})
.catch((err) => {
cache.status = "rejected";
cache.value = err;
});
throw promise;
}
window.fetch = myFetch;
// 3. 运行func
try {
func();
} catch (err) {
if (err instanceof Promise) {
err.finally(() => {
window.fetch = myFetch;
func();
window.fetch = oldFetch;
});
} else {
console.log(err.message);
}
}
// 4. 恢复fetch
window.fetch = oldFetch;
}
run(main);
function myFetch(url) {
return new Promise((resolve, reject) => {
throw new Error("中断执行");
fetch(url);
fetch(url).then((res) => {
resolve(res);
});
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 判断两个字符串中的数字的大小
通过一个生成器函数来从头迭代这 2 个字符串,如果相等就继续比较下一个数字,如果不相等就返回数字较大的字符串。
function* walk(str) {
let s = "";
for (let c of str) {
if (c === "-") {
yield Number(s); // Number()===Number('')===Number(false)===Number([])===Number('0')===Number(0)===0
s = "";
} else {
s += c;
}
}
if (s) {
yield Number(s);
}
}
function compare(str1, str2) {
const iter1 = walk(str1);
const iter2 = walk(str2);
while (true) {
const { value: v1, done: d1 } = iter1.next();
const { value: v2, done: d2 } = iter2.next();
if (d1 && d2) {
return 0; // 相等
}
if (d1) {
return -1; // str1 小
}
if (d2) {
return 1; // str2 小
}
if (v1 < v2) {
return -1;
}
if (v1 > v2) {
return 1;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# em 和 rem 的区别
em 和 rem 是 CSS 中用于设置相对单位的两种测量方式,它们的主要区别在于它们的计算基准不同。
- em 是一个相对单位,其基准是元素自身的字体大小。
- 当你在一个元素上使用 em 单位时,它的值是相对于该元素的字体大小来计算的。
- 如果在某个元素内嵌套了另一个元素,那么内嵌元素的 em 单位将会继承其父元素的字体大小,从而产生乘法效应。
- rem 是根元素的相对单位,其基准是根元素的字体大小(即 html 标签)。 -不管元素的层级如何,使用 rem 单位时,它的值总是相对于
<html>元素的字体大小来计算。- 这意味着 rem 单位不会受到嵌套元素的影响。
# 前端加载图片
# CSS 中的 background 属性来实现
利用 CSS 的 background 属性将图片预加载到屏幕外的背景上。只要这些图片的路径保持不变,当它们在 Web 页面的其他地方被调用时,浏览器就会在渲染过程中使用预加载(缓存)的图片。简单、高效,不需要任何 JavaScript。该方法虽然高效,但仍有改进余地。使用该法加载的图片会同页面的其他内容一起加载,增加了页面的整体加载时间。
# 使用 JavaScript 方式来实现
在 JS 中利用 Image 对象,为元素对象添加 src 属性,将对象缓存起来待后续使用。
//banner img 高清加载
function imgdownLoad(){
var setImg = function(imgLgUrl) {
if(imgLgUrl) {
var imgObject = new Image();
imgObject.src = imgLgUrl;
if(imgObject.complete){ //发现缓存则加载缓存
$img.attr("src", imgLgUrl);
return ;
}
imgObject.onload = function(){ //图片加载完成后替换图片
$img.attr("src", imgLgUrl);
}
}
}
$("img").each(function(){
var $img = $(this);
var imgLg = $img.attr("data-imglg"); //高清
var imgMd = $img.attr("data-imgmd"); //中等
var imgSm = $img.attr("data-imgsm"); //一般
setImg(imgSm);
setImg(imgMd);
setImg(imgLg);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 计算页面滚动位置进行预加载
先给图片设置统一的占位图,然后再根据页面滚动情况使用自定义属性data-src去加载图片。
<body>
<div>
<img class="lazy-load" data-src="https://fakeimg.pl/600x200" alt="images" />
<img class="lazy-load" data-src="https://fakeimg.pl/700x200" alt="images" />
<img class="lazy-load" data-src="https://fakeimg.pl/800x200" alt="images" />
<img class="lazy-load" data-src="https://fakeimg.pl/900x200" alt="images" />
</div>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/lodash.min.js" type="text/javascript"></script>
<script type="text/javascript">
let lazyImages = [...document.querySelectorAll(".lazy-load")];
let inAdvance = 300;
function lazyLoad() {
console.log("lazyLoading...");
lazyImages?.forEach((image) => {
if (image.offsetTop < window.innerHeight + window.pageYOffset + inAdvance) {
image.src = image.dataset.src;
}
});
}
lazyLoad();
window.addEventListener("scroll", _.throttle(lazyLoad, 50));
window.addEventListener("resize", _.throttle(lazyLoad, 50));
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 每次加载一张图片
通过 onload 事件判断 Img 标签加载完成。
const imgArrs = [
"https://fakeimg.pl/100x200",
"https://fakeimg.pl/200x200",
"https://fakeimg.pl/300x200",
"https://fakeimg.pl/400x200",
"https://fakeimg.pl/500x200",
"https://fakeimg.pl/600x200",
]; // 图片地址
const content = document.getElementById("content");
const loadImg = () => {
if (!imgArrs.length) return;
const img = new Image(); // 新建一个Image对象
img.src = imgArrs[0];
img.setAttribute("class", "img-item");
img.onload = () => {
// 监听onload事件
// setTimeout(() => { // 使用setTimeout可以更清晰的看清实现效果
content.appendChild(img);
imgArrs.shift();
loadImg();
// }, 1000);
};
img.onerror = () => {
// do something here
};
};
loadImg();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# img 标签加载时机
img 标签是什么时候发送图片资源请求的?
- HTML 文档渲染解析,如果解析到 img 标签的 src 时,浏览器就会立刻开启一个线程去请求图片资源。
- 动态创建 img 标签,设置 src 属性时,即使这个 img 标签没有添加到 dom 元素中,也会立即发送一个请求。
const img = new Image();
img.src = "https://fakeimg.pl/100x200";
2
- 创建了一个 div 元素,然后将存放 img 标签元素的变量添加到 div 元素内,而 div 元素此时并不在 dom 文档中,页面不会展示该 div 元素,那么浏览器会发送请求吗?-- 会!
- 通过设置 css 属性能否做到禁止发送图片请求资源?-- 不一定
- 给 img 标签设置样式
display: none或者visibility: hidden,隐藏 img 标签,无法做到禁止发送请求。 - 将图片设置为元素的背景图片
background-image,但此元素不存在,可以做到禁止发送请求。dom 文档中不存在 class 为 test 的元素时,即使给 test 这个 class 设置了背景图片,也不会发送请求,只有有使用到 test 这个 class 的元素存在时才会发送请求。
- 给 img 标签设置样式
<style>
.test {
background-image: url("https://fakeimg.pl/300x200");
}
</style>
<div id="container">
<div class="test1">test background-image</div>
<img src="https://fakeimg.pl/100x200" style="display: none" />
<img src="https://fakeimg.pl/200x200" style="visibility: hidden" />
</div>
<script>
const img = `<img src='https://fakeimg.pl/600x200'>`;
const dom = document.createElement("div");
dom.innerHTML = img;
// document.body.appendChild(dom);
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# iframe 相关
# 父子页面通信问题
iframe 和父页面是两个独立的上下文环境,这使得父子页面之间的通信变得复杂。父页面想操作 iframe 内的 Vue 子应用数据(或者反过来)。如果 iframe 加载的是跨域内容,直接访问 iframe 的内容会触发 跨域限制。
- 同源情况:使用 window.postMessage 做通信,父子页面同源时,可以通过 postMessage 实现数据通信:
- 跨域情况:后端接口代理,如果 iframe 加载的是跨域资源,推荐通过后端代理实现同源加载,或者借助中间服务器转发通信。
# iframe 加载速度慢,阻塞父页面性能
iframe 的加载是一个独立的网络请求和渲染过程,如果其加载的内容较多或速度较慢,会影响父页面的性能表现。iframe 加载时间过长,页面白屏。iframe 的加载和渲染阻塞了父页面的交互。
- 懒加载 iframe,仅在需要时加载 iframe,可以使用 Vue 的 v-if 或动态绑定 src 的方式
- 异步加载机制,在大部分场景中,可以通过设置占位符(如加载动画)来提升用户体验,避免长时间白屏。
- 优化 iframe 加载速度,使用懒加载、预加载、CDN 等优化技术,减少 iframe 加载时间。
# 样式和滚动条问题
iframe 独立的 CSS 环境可能导致样式问题,尤其是父页面需要控制 iframe 的样式时非常困难。此外,iframe 内部的滚动条可能会影响用户体验。iframe 内样式与父页面不一致。父页面滚动和 iframe 滚动冲突。
- 控制 iframe 的样式:通过注入 CSS。如果你能控制 iframe 加载的内容,可以在父页面通过 contentWindow.document 动态注入样式
const iframe = document.getElementById("myIframe");
const style = document.createElement("style");
style.textContent = "body { margin: 0; overflow: hidden; }";
iframe.contentWindow.document.head.appendChild(style);
2
3
4
- 隐藏滚动条,为 iframe 添加样式,隐藏滚动条
iframe {
overflow: hidden;
scrollbar-width: none; /* Firefox */
}
iframe::-webkit-scrollbar {
display: none; /* Chrome, Safari */
}
2
3
4
5
6
7
- 同步滚动条,如果需要让父页面和 iframe 的滚动同步,可以监听 iframe 的滚动事件,并同步父页面的滚动:
iframe.contentWindow.onscroll = () => {
const scrollTop = iframe.contentWindow.scrollY;
document.documentElement.scrollTop = scrollTop;
};
2
3
4
# 跨域限制问题
当 iframe 加载跨域资源时,JavaScript 不能直接访问 iframe 的内容。这是浏览器的同源策略所决定的,目的是为了安全性。父页面无法操作或获取 iframe 内的内容。无法控制 iframe 内的 DOM 或数据。
使用 postMessage 通信:跨域情况下,父页面与 iframe 可以使用 postMessage 的消息机制来通信(如前面提到的方案)。
后端代理实现同源:如果你有后端支持,可以通过后端代理 iframe 的内容,使其与父页面同源,从而绕过跨域限制。
JSONP 或 CORS:如果是请求数据,可以尝试使用 JSONP 或配置服务器支持 CORS。
# SEO 和路由问题
iframe 内容对搜索引擎来说是不可见的,这会对 SEO 产生负面影响。此外,在 Vue 应用中,如果 iframe 是动态路由的一部分,可能会引发路由管理混乱。iframe 的内容不会被搜索引擎索引。Vue 的动态路由和 iframe 的加载冲突(如刷新时丢失状态)
避免用 iframe 承载重要内容:如果需要 SEO,尽量避免将核心内容放在 iframe 中,可以用 Vue 的组件化来代替。
使用 Vue 的路由守卫管理 iframe:如果 iframe 是动态路由的一部分,可以通过 Vue 的路由守卫动态设置 iframe 的内容:
// router/index.js
const routes = [
{
path: '/iframe/:src',
component: () => import('@/views/IframePage.vue')
}
];
// IframePage.vue
<template>
<iframe :src="iframeSrc" frameborder="0"></iframe>
</template>
<script>
export default {
computed: {
iframeSrc() {
return this.$route.params.src;
}
}
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 安全问题(XSS 攻击)
如果 iframe 加载的是第三方页面,可能会引入潜在的安全风险,例如跨站脚本攻击(XSS)。加载的内容中可能存在恶意脚本。父页面受到安全隐患的影响。
设置 sandbox 属性:通过设置 iframe 的 sandbox 属性限制其行为:
<iframe src="https://example.com" sandbox="allow-scripts allow-same-origin"></iframe>内容安全策略(CSP):在后端或 HTML 中设置 CSP,以限制 iframe 加载的资源:
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; frame-src 'self' https://example.com;">
# 正则表达式匹配路径
# React18 与 Vue3 组件通信
Vue 还有一种特殊的方式:attrs/useAttrs,attrs 是一个特殊的对象,在组件中,可以访问并使用未被显式声明为 props 的属性,是有状态的对象,它总是会随着组件自身的更新而更新,主要用于将父组件的非 props 特性传递给子组件,特别适用于创建包装组件或高阶组件。如果关闭了export default defineComponent({inheritAttrs: false,}); // 关闭自动继承父属性,那么需要通过<button v-bind="$attrs" @click="$emit('click')">v-bind 的形式显式绑定来自父组件的属性,比如:id、class 等。在组件中,默认情况下,attrs 会被自动绑定到组件的根元素。如果不想让它自动绑定,可以设置 inheritAttrs: false。这样,你就可以手动控制哪些属性和事件被传递。attrs 适合用于将父组件的多个属性转发给子组件的场景。如果你需要将组件的某些状态或数据与多个子组件共享,你可能更倾向于使用 Vue 3 的其他特性,如 provide/inject、Vuex 或 Composition API。虽然可以使用 attrs 来在某种程度上进行组件间的通信,但对于状态管理和数据流动,使用 props 和事件是更常见和推荐的方式。
# 全局的通信方法
- React 中使用 Context 或者 Redux 等状态管理库
- Vue3 中使用 Pinia 或者 Vuex 等状态管理库
- 通过事件总线实现
# 父子组件通信
- 在 React 中,父子组件通信是通过 props 实现的。父组件向子组件传递数据,子组件通过 props 接收,子组件通过 props 传入的回调函数来修改父组件的状态。
- 在 Vue3 中,父子组件通信是通过 props 和 $emit 实现的。父组件向子组件传递数据,子组件通过 defineProps 接收。子组件向父组件传递数据通过 $emit 触发父组件中的函数实现。父组件
<Son @sendMessage="receiveMessage" />并定义 receiveMessage 方法接收返回的参数,子组件const emit = defineEmits(['sendMessage']);emit('sendMessage', '我是Son组件');,可以声明 emit 的事件,以保留对事件的类型检查和编译时验证。 - 在 Vue3 中,如何在父组件调用子组件时传递方法,并让父组件获取子组件内部的方法或属性?子组件需要明确地暴露这些方法和属性。这可以通过使用 defineExpose 来实现。随后,父组件可以通过 ref 或 useTemplateRef 来引用子组件实例,从而调用其暴露的方法或访问其属性。
# 兄弟组件通信
- 通过将「共享的状态提升」到父组件来实现。父组件将该状态和修改状态的函数通过 props 传递给子组件。再借助 emit 进行通信。
- 使用 EventBus:创建一个 EventBus 对象,用于在组件之间传递事件。在需要通信的组件中,使用 EventBus 发布事件,然后在另一个组件中监听该事件。
# 跨层级组件通信
- 层层 props 传下去,麻烦,不好维护。
- React 中,使用 Context:在需要通信的组件中,使用 Context.Provider 提供数据,然后在另一个组件中通过 Context.Consumer 订阅数据。
- createContext 创建 context 对象,上下文 ctx 对象将包含你希望在组件树中共享的数据。
- Provider 提供器,包裹需要跨层通信的组件。将数据通过 value 属性传递给 Provider,任何位于 Provider 内部的组件都可以访问到这些数据。
- useContext 钩子来访问上下文中的数据。useContext 接受一个上下文对象(就是通过 createContext 创建的那个对象)作为参数,并返回该上下文的当前值。
- Vue3 中,使用 provide/inject:在需要通信的组件中,使用 provide 提供数据
provide('msg', msg);,然后在另一个组件中使用 inject 获取数据const msg = inject('msg');。
# 浏览器盒模型
# 手写 Promise.all
# js 隔离原理
# CDN 缓存策略
# XSS 和 CSRF
CSRF 原理和解决方案
# websocket 消息质量保证
012 段消息是什么
# websocket 通信机制
# 前端性能优化
# 面向对象编程和面向过程编程的区别和理解
# 大数据渲染造成的页面卡顿怎么优化
# 为什么要使用虚拟 DOM
# 有效括号匹配
栈,先入栈左侧,遇到右侧就从栈顶 pop 一个出来,如果不匹配就 false,否则继续 push 入栈,最后看栈是否清空。
# 判断 b 是否是 a 的子集
ab 有重复元素,要求 b 中相同元素出现的次数<=a 中的
# 302 怎么确定重定向路径
# 几种 worker 的对比
| 特性 | Web Worker | Service Worker | Shared Worker |
|---|---|---|---|
| 目的 | 处理后台任务,专注于防止 UI 阻塞 | 控制网络请求和离线功能 | 共享状态或数据,提供一个共享的上下文以便多个浏览器上下文之间的通信。 |
| 访问 DOM | 不可访问 | 不可访问 | 不可访问 |
| 共享性 | 不共享 | 不共享 | 共享多个上下文 |
| 生命周期 | 由调用者管理 | 有独立生命周期 | 由调用者管理 |
| 通信方式 | postMessage | 事件驱动 | MessagePort |
| 使用场景 | CPU 密集型处理 | 离线缓存、推送通知 | 多窗口/标签页共享数据 |
# 全排列
回溯算法模板,一种方式是递归,循环遍历各个数字字符,先存到 path 中,然后递归剩下的数字字符,递归结束后 pop 恢复现场,继续循环。终止条件是path.length===nums.length。
# 前端路由原理
- hashchange 事件:hash 路由
- popstate 事件:history 路由
- history.pushState()
- history.replaceState()
# Vue 动态加载组件
- 使用异步组件:异步组件允许在需要时动态加载 Vue 组件,通常结合 import() 语法来实现。这样可以将组件分割到不同的文件中,只有在需要时才加载。动态的引入组件。配合
<component :is="currentComponent"></component>实现。 - 使用动态组件:Vue 提供了一种 component 组件,可以根据绑定的值动态切换组件,这对于动态加载组件也十分有用。提前注册组件,动态设置组件名。配合
<component :is="currentComponent"></component>实现。 - 使用 Vue Router 的路由懒加载:如果你使用 Vue Router 管理路由,也可以通过路由懒加载实现组件的动态加载。也是通过 import()动态引入组件。
- 结合 Vuex 进行动态管理:如果需要根据某些条件从状态管理中动态加载组件,可以结合 Vuex 实现。在 commit 时动态 import 引入所需组件。
- 插槽,传入要展示的组件,配合
<component :is="currentComponent"></component>实现。 - 频繁切换时借助 keep-alive 组件进行缓存
# is 的实现原理是什么?
<component :is="currentComponent"></component>
# Hash 路由与 History 路由的对比
| 特性 | Hash 路由 | History 路由 |
|---|---|---|
| URL 格式 | http://example.com/#/page1 | http://example.com/page1 |
| 兼容性 | 所有浏览器,包括旧版浏览器 | 现代浏览器,旧版浏览器可能不支持 |
| SEO 友好 | 不友好 | 友好 |
| 用户体验 | URL 中有 # 符号,视觉上不美观 | 更干净的 URL,没有哈希符号 |
| 刷新行为 | 刷新时会根据哈希重新渲染内容 | 刷新时需要服务器支持来处理 URL |
| 实现复杂性 | 实现简单,使用 hashchange 事件 | 需要管理历史记录、状态等 |
| 原理 | hashchange 事件 | history.pushState/replaceState 和 popstate 事件 |
# history 路由的 Nginx 配置
假设你的应用构建后的文件存放在 /usr/share/nginx/html 目录中,并且你的 index.html 文件位于该目录下。可以参考以下配置:
server {
listen 80; # 监听端口
server_name example.com; # 你的域名或 IP
location / {
root /usr/share/nginx/html; # 应用文件所在目录
index index.html; # 默认首页文件
try_files $uri $uri/ /index.html; # 尝试请求文件,如果文件不存在则返回 index.html
}
# 可选:配置 gzip 压缩
gzip on;
gzip_types text/plain application/javascript application/x-javascript text/css application/json;
gzip_min_length 1000;
# 可选:配置缓存
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg)$ {
expires 1y; # 缓存一年
add_header Cache-Control "public, max-age=31536000, immutable";
}
# 可选:错误页面处理
error_page 404 /index.html; # 404 错误也返回 index.html
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
修改 Nginx 配置后检查并重启。
sudo nginx -t # 测试配置是否正确
sudo systemctl reload nginx # 重新加载 Nginx
2
# v-for 和 v-if 执行优先级
**不推荐在一元素上同时使用这两个指令 **
- Vue2 中:当同时使用时,v-for 比 v-if 优先级更高。
- Vue3 中:当同时使用时,v-if 比 v-for 优先级更高。
# 页面白屏检测
# ref 和 reactive 的区别
- 实现原理
- 使用方法
# props 数据流向
# 发布订阅模式和观察者模式的区别
# input 怎么确定 schema 结构
# nodejs 内存泄漏怎么解决
Node.js 内存泄漏是指程序在执行过程中不再使用的内存没有被及时释放,导致内存的逐渐增加,这可能会导致应用程序性能下降甚至崩溃。解决内存泄漏的问题需要从多个方面着手。
- 常见的内存泄漏原因
- 全局变量:意外地将变量声明为全局变量,导致其在整个应用生命周期中保持活跃。
- 事件监听器:未注销的事件监听器会导致内存泄漏。
- 闭包:闭包中引用了外部变量,但这些外部变量不再需要,从而无法被垃圾回收。
- 长时间运行的定时器:使用 setInterval 或 setTimeout 却没有在适当的时候清除它们。
- 缓存的引用:在数据缓存中存储大量对象,但没有适时清除。
- 解决内存泄漏的方法
- 使用堆分析工具:Node.js 内置的 V8 堆快照:可以使用 Chrome DevTools 的远程调试功能来分析 Node.js 应用的内存使用情况。Heapdump:可以在应用运行时生成堆快照,便于后续分析。在 Chrome DevTools 中打开该堆快照文件进行分析。
- 定期清理不再使用的对象:确保及时清理不再使用的对象和数据。例如,使用 WeakMap 和 WeakSet 来创建不会阻止垃圾回收的引用。
- 取消事件监听器:在不再需要时,及时取消事件监听器,特别是在使用 EventEmitter 时
- 清理定时器和异步任务:确保使用 clearTimeout 和 clearInterval 清理不再需要的定时器。
- 避免使用全局变量:尽量减少全局变量的使用,避免不必要的全局引用。可以使用模块导出和封装方法来管理应用状态。
- 使用内存监控工具:PM2:一个进程管理工具,提供内存监控功能。Node Clinic:用于性能分析的工具,可以帮助识别内存泄漏。
# 多窗口之间怎么通信
# 捕获和冒泡事件触发顺序
- 捕获阶段:事件从外层元素传播到目标元素。
- 目标阶段:目标元素的事件处理程序被调用。
- 冒泡阶段:事件从目标元素向外层元素传播。
默认情况下,addEventListener 的第三个参数为 false,表示使用冒泡阶段。如果将其设置为 true,则事件将在捕获阶段被处理。
# 数据大屏怎么实现响应式
- 使用响应式框架:Bootstrap:提供了强大的栅格系统和组件,适合快速开发响应式布局。Tailwind CSS:采用实用程序优先的 CSS 方法,可以轻松创建响应式设计。Ant Design 或 Material UI:这两者都是基于 React 的 UI 组件库,具有响应式设计的理念。
- 媒体查询:通过 CSS 媒体查询,可以为不同的屏幕尺寸应用不同的样式。
- 使用 Flexbox 或 CSS Grid 布局可以更灵活地创建响应式设计。
- 响应式图表:如果数据大屏中包含图表,确保使用支持响应式的图表库:Chart.js:可以自动适应容器大小。ECharts:提供了良好的响应式支持,可以通过配置自动调整图表大小。AntV:企业级数据可视化解决方案。
- 动态调整布局:可以使用 JavaScript 监听窗口大小变化,动态调整布局,监听 resize 事件,做相应处理。
# 浏览器访问 url 过程
硬件加速方案,优缺点;DNS 解析过程、预解析、耗时指标
# 单点登录和 SSO 鉴权
授权协议
# nodejs 是单线程吗?怎么提高并发量
- Node.js 是基于事件驱动的非阻塞 I/O 模型,虽然它本身是单线程的,但可以通过一些方式提高并发量和性能。
- 单线程:Node.js 的主事件循环运行在单个线程上,所有 I/O 操作(如文件读取、网络请求等)都是异步的,使用事件和回调来处理。
- 事件循环:Node.js 的事件循环机制能够处理大量的连接请求,而不需要为每个请求创建一个线程。它使用事件和回调机制来处理请求,使得在等待 I/O 的同时可以处理其他任务。
提高 Node.js 并发量的方法:
- 使用 Cluster 模块:Node.js 的 Cluster 模块可以创建多个工作进程,每个进程都有自己的事件循环和内存空间。这允许你充分利用多核 CPU 的优势。
// 主进程会为每个 CPU 核心创建一个工作进程,能够同时处理多个请求。
const cluster = require("cluster");
const http = require("http");
const numCPUs = require("os").cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
http
.createServer((req, res) => {
res.writeHead(200);
res.end("Hello World\n");
})
.listen(8000);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 使用负载均衡器:在生产环境中,可以使用负载均衡器(如 NGINX 或 HAProxy)将请求分发到多个 Node.js 实例。这种方式能够进一步提高并发处理能力。
- 异步 I/O 优化:确保使用 Node.js 提供的异步 API 来处理 I/O 操作,避免使用阻塞的代码。使用异步操作可以使事件循环继续处理其他请求。
- 使用 Redis 进行消息队列:在某些情况下,使用 Redis 等消息队列来处理长时间运行的任务可以提高并发能力。通过将任务放入队列,可以让 Node.js 继续处理其他请求,而后台 worker 处理这些耗时任务。
- 连接池:对于数据库等外部服务,使用连接池可以减少连接的创建和销毁的开销,提高并发性能。确保数据库连接的管理是高效的。
- 使用 WebSocket 和长轮询:对于需要处理大量实时数据的应用,可以使用 WebSocket 或长轮询实现高效的实时通信,这样能够更好地处理高并发请求。
- 性能监控与调优:使用性能监控工具(如 PM2、New Relic、DataDog 等)来监控应用性能,识别瓶颈并进行优化。
# 前端监控告警体系
性能监控的指标有哪些?页面加载的瓶颈和优化手段
# 在哪些情况下一个元素绑定的点击事件不会被触发?
- 元素不可见或被遮挡:
- CSS 隐藏:如果元素的 display 属性被设置为 none,则该元素不会在页面上展示,点击事件自然不会被触发。
- 透明度:如果元素的 opacity 属性为 0,它仍然可以占据空间,但是用户无法看到它,因此也不会触发点击事件。
- 遮挡其它元素:如果一个元素被其他元素遮挡(如使用 z-index 进行层叠),则无法点击该元素。
- 事件被阻止
event.preventDefault():如果在事件处理程序中调用了event.preventDefault(),某些默认行为(如链接跳转)将被阻止,但这不会影响点击事件本身的触发。event.stopPropagation():如果在事件处理程序中调用了event.stopPropagation(),那么事件可能不会向上传递,特别是在嵌套元素中,但这并不会阻止事件本身的触发。
- 元素处于失去焦点状态
- 表单元素:如果某些表单元素(如 button 或 input)在失去焦点时可能不响应点击事件,尤其是在某些浏览器中。
- 错误的事件绑定
- 使用了错误的选择器。
- 在 DOM 元素未加载时绑定事件(如在 DOMContentLoaded 之前)。
- 元素被禁用
- disabled 属性:如果元素是一个表单控件(例如
- JavaScript 错误:在事件处理程序中,如果出现 JavaScript 错误,可能会导致后续代码(包括绑定的事件)不被执行。
- 使用了 pointer-events CSS 属性:如果元素的
pointer-eventsCSS 属性被设置为 none,则该元素将不会响应任何鼠标事件,包括点击。 - 移动设备的特殊情况:在某些移动设备上,未处理的触摸事件(如 touchstart 或 touchend)可能会影响点击事件的触发。
- 使用了框架或库中的事件处理机制:在使用某些 JavaScript 框架(如 React、Vue.js 等)时,事件的管理可能与原生 JavaScript 不同,需遵循框架的事件处理方式。
# Vue3 系列
# 静态图片动态加载
Vite 打包时会自动进行依赖分析,导致有些图片会直接打包到静态资源中,而其他图片则需要通过动态导入的方式加载,因此需要使用动态导入的方式加载静态图片。
- 通过标签引入静态图片:img、video、audio 等标签的 src 属性,通过动态导入的方式加载静态图片。
- 通过 CSS 引入静态图片:在 CSS 文件中通过 background-image 属性引入静态图片。
- 把图片放到 public 目录下,通过相对路径引入。打包时会自动将图片复制到 dist 目录下,但会丢失图片的 hash 值。
- 通过
import('./assets/${img}.jpg').then(p=>path=p.default)函数引入静态图片,通过 then()方法获取图片的 URL。但会产生很多 js 文件。而且要 path 中不能完全是变量,否则会导致路径解析错误。 - 通过
new URL('./assets/${img}.jpg', import.meta.url),然后使用 url 对象来赋值。
# Vue3 setup 中如何获得组件实例
- Vue3 的 setup 函数是在组件创建之前执行的,这时候组件实例还没有完全生成,所以在 setup 函数内部直接使用 this 是无效的,因为 this 指向的是 undefined 或者不是组件实例。使用 getCurrentInstance 函数,这是 Vue3 提供的一个 API,用于获取当前组件的实例。但是需要注意,getCurrentInstance 返回的是一个内部实例,并不是公共 API 的一部分,因此在使用时需要谨慎,避免依赖内部实现细节。-- 不推荐
setup() {
const instance = getCurrentInstance();
// 通过 instance 访问组件上下文
console.log(instance.proxy); // 等效于 Vue2 的 this
console.log(instance.ctx); // 上下文对象
console.log(instance.parent); // 父组件实例
console.log(instance.refs); // 模板中的 ref 引用
return {
instance
}
}
2
3
4
5
6
7
8
9
10
11
- 如果需要获取组件实例,可以使用 ref 来获取。在 setup 函数中,使用 ref 来获取组件实例或者获取 DOM 元素,使用 ref 函数来创建一个响应式引用,然后在模板中绑定这个 ref,从而在 setup 函数中访问到对应的 DOM 元素或组件实例,然后就可以在模板中使用。在 onMounted 后使用确保组件已挂载。-- 推荐
# Vue 的 watch 有哪些配置项?和 computed 的区别?和 watchEffect 的区别?
Vue 的 watch 有哪些配置项?
immediate:当监听的值第一次被赋值时,会立即执行回调函数。
handler:当监听的值发生变化时,会执行的回调函数。接收 newval 和 oldval。
deep:当监听的对象是嵌套对象时,设置为 true 可以监听对象内部属性的变化。
flush:控制回调函数的执行时机,可选值为 'pre'、'post'、'sync'。
- 默认值为 'pre',即在微任务队列清空后执行。即 prop 更新完之后触发回调函数再更新 DOM(此时回调函数里不能通过 DOM 获取到更新后的 prop 的值)。
- 设置为 'post' 会在宏任务队列清空后执行。则更新完 prop 之后再更新 DOM 然后再触发回调函数(此时回调函数里就能通过 DOM 获取到更新后的 prop 的值)。
watchPostEffect - 设置为 'sync' 会在当前任务执行完毕后立即执行。则回调函数会同步执行,也就是在响应式数据发生变化时立即执行,会在 Vue 进行任何更新之前触发。
watchSyncEffect,同步侦听器不会进行批处理,每当检测到响应式数据发生变化时就会触发。可以使用它来监视简单的布尔值,但应避免在可能多次同步修改的数据源 (如数组) 上使用。
onTrack / onTrigger:调试侦听器的依赖。
once:默认为 false,回调函数只会运行一次。侦听器将在回调函数首次运行后自动停止。
Vue 的 watch 和 computed 和 method 的区别
- 计算属性 computed 在第一次计算完成后,会对结果进行缓存,后续再次调用时直接输出结果而不会重新计算。仅当依赖变化时再重新计算并缓存,计算量较大时使用计算属性会更高效。频繁使用时使用计算属性会更高效。
- method 调用几次就会执行几遍,不会缓存结果,每次都会重新计算。
- watch 用于监听数据的变化,当数据变化时,会执行回调函数,回调函数接收新值和旧值。
Vue 的 watch 和 watchEffect 的区别
watchEffect 直接接收一个回调函数,会自动追踪函数内部使用到的响应式数据变化,数据变化时重新执行该函数
watchEffect 的函数会立即执行一次,并在依赖的数据变化时再次执行
watchEffect 更适合简单的场景,不需要额外的配置,相当于默认开启了 deep 和 immediate 的 watch
watchEffect 也能接收第二个参数,用来配置 flush 和 onTrack / onTrigger,拿不到旧值
watch 显示的接收一个需要被监听的数据和回调函数,若监听的数据发生变化,重新执行该函数
watch 的回调函数只有在侦听的数据源发生变化时才会执行,不会立即执行
watch 可以更精细的控制监听行为,如 deep、immediate、flush 等,可以终止监听,可以拿到旧值
watch 第一个参数可以是一个数组,监听多个数据源,也可以是一个对象,对象中的 key 为数据源,value 为回调函数,还可以是一个函数(最终都会转成函数),如果这个函数返回的值不变,则回调函数也不会执行,即使在函数中依赖的响应式数据发生了变化。
一个关键点是,侦听器必须用同步语句创建:如果用异步回调(比如 setTimeout)创建一个侦听器,那么它不会绑定到当前组件上,你必须手动停止它,以防内存泄漏。
总结:它们之间的主要区别是追踪响应式依赖的方式:
watch 只追踪明确侦听的数据源。它不会追踪任何在回调中访问到的东西。另外,仅在数据源确实改变时才会触发回调。watch 会避免在发生副作用时追踪依赖,因此,我们能更加精确地控制回调函数的触发时机。
watchEffect,则会在副作用发生期间追踪依赖。它会在同步执行过程中,自动追踪所有能访问到的响应式属性。这更方便,而且代码往往更简洁,但有时其响应性依赖关系会不那么明确。
# Vue3 中的宏有哪些?
- defineProps: 声明 props
- defineEmits: 声明 emit
- defineModel: 用来声明一个双向绑定 prop
- defineExpose: 指定对外暴露组件的属性
- defineOptions:在 script setup 中提供组组件属性
- defineSlots: 声明 slots
# Vue3 声明一个响应式数据的方式?
- ref: 通过.value 访问及修改
- reactive: 直接访问、只能声明引用数据类型
- computed: 也是通过.value,声明需要 传 get、set
- toRef: 类似 ref 的用法,可以把响应式数据的属性变成 ref
- toRefs: 可以把响应式数据所有属性 转成一个个 ref
- shallRef: 浅层的 ref,第二层就不会触发响应式
- shallReactive: 浅层的 reactive,第二层就不会触发响应式
- customRef: 自定义 ref
# v-memo
缓存一个模板的子树。在元素和组件上都可以使用。为了实现缓存,该指令需要传入一个固定长度的依赖值数组进行比较。如果数组里的每个值都与最后一次的渲染相同,那么整个子树的更新将被跳过。仅用于性能至上场景中的微小优化,有助于渲染海量 v-for 列表 (长度超过 1000 的情况)。
一般与 v-for 配合使用,v-memo 的值是一个数组。当组件重新渲染,如果数组的值不改变的情况,该组件及子组件所有更新都将被跳过,只要 v-memo 绑定的数组的值没改变,即使子组件引用的响应数据变了,也不会更新。甚至虚拟 DOM 的 vnode 创建也将被跳过。直接重用缓存的子树副本。
# computed 的 getter 和 setter
- getter:计算属性的 getter 是一个函数,当访问计算属性时,会执行这个 getter 函数,返回计算属性的值。
- setter:计算属性的 setter 是一个函数,当修改计算属性的值时,会执行这个 setter 函数,传入新值和旧值。可以在这里修改计算属性的值,也可以在这里执行一些副作用操作。也就是说可以在 method 中直接对计算属性赋新值,就像处理普通的 data 一样,然后在 setter 中对新值进行处理。
- 计算属性的 getter 和 setter 可以用来实现双向数据绑定,即当计算属性的值发生变化时,会自动更新依赖该计算属性的其他数据;当依赖该计算属性的其他数据发生变化时,会自动更新计算属性的值。
# provide 和 inject
- provide 和 inject 是 Vue 中的两个 API,用于实现组件间的数据传递和依赖注入。
- provide 是一个 provide 方法,用于提供当前组件的属性和方法,供其他组件使用。
provide('message', message);或在应用顶层app.provide(/* 注入名 */ 'message', /* 值 */ 'hello!') - inject 是一个 inject 方法,用于注入当前组件的属性和方法,供其他组件使用。在组件中
const message = inject('message'[, defaultValue, true]);,第二个参数表示默认值,可以是一个具体的值也可以是个函数,第三个参数表示默认值应该被当作一个工厂函数。在一些场景中,默认值可能需要通过调用一个函数或初始化一个类来取得。为了避免在用不到默认值的情况下进行不必要的计算或产生副作用,我们可以使用工厂函数来创建默认值 - provide 和 inject 的作用是让组件之间可以相互传递数据,而不需要通过父组件传递到子组件,再由子组件传递到孙组件,这样会增加组件的层级,导致组件嵌套过深,维护起来非常麻烦。
- provide 注入的值可以是任意类型,包括响应式的状态,比如一个 ref,那么此时 inject 接收到的会是该 ref 对象,而不会自动解包为其内部的值。这使得注入方组件能够通过 ref 对象保持了和供给方的响应性链接。这表明:provide+inject 注入的值可能是响应式的也可能是非响应式的。
- 使用时,如果没有使用
<script setup>,provide()/inject()都需要在setup()内同步调用。 - 当提供 / 注入响应式的数据时,建议尽可能将任何对响应式状态的变更都保持在供给方组件中。这样可以确保所提供状态的声明和变更操作都内聚在同一个组件内,使其更容易维护。
- 如果你想确保提供的数据不能被注入方的组件更改,你可以使用
readonly()来包装提供的值。provide('read-only-count', readonly(count))。
# 对象的动态属性和静态属性
# 实现页面自动检测页面是否更新
- 轮询
- websocket
- SSE
- 可以约定设置一个特定的 js 文件放在 head 中,js 文件要打上指纹(hash)以便于对比版本,然后前端通过轮询的方式去请求这个 js 文件,如果文件的指纹发生变化,说明文件有更新,前端就可以重新加载这个 js 文件,从而实现页面的自动检测更新。
# forEach 原理
forEach 在循环开始之前,会先获取数组的初始长度并存下来,所以即使在 forEach 循环中增加数组的长度,循环的次数也不会受影响。但是如果减少了数组的长度,由于在取值时会判断当前属性是否存在于数组中(if(k in o)...),所以循环次数也会减少。不能通过 return、break、continue 来中断循环。
Array.prototype.myForEach = function (callback, thisArg) {
if (this === null || this === undefined) {
throw new TypeError("Array.prototype.myForEach called on null or undefined");
}
let obj = this;
let len = obj.length;
if (typeof callback !== "function") {
throw new TypeError("callback不是函数");
}
for (let i = 0; i < len; i++) {
if (i in obj) {
let val = obj[i];
callback.call(thisArg, val, i, obj);
}
}
return undefined;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Promise
- Promise 中的内部发生的错误在 try/catch 中无法捕获,需要在 Promise 的 catch 中捕获,或者需要 async/await 和 try/catch 配合使用才能捕获错误。
- try/catch 捕获的是 try 中报的错或者 throw 的 Error。
# async、await 的原理和优势
- async/await 是基于 Promise 的语法糖,可以简化异步代码的编写,使得异步代码看起来更像同步代码。
- async 用于声明一个异步函数,await 用于等待一个异步方法执行完成。在浏览器控制台环境中,目前这俩关键字是可以分开单独使用的。
- 在普通函数前面加上 async 之后,这个函数会返回一个 Promise 对象,如果函数中本身就有 return 的内容,那么就相当于返回一个已经解决的 Promise 对象,如果函数中抛出错误,那么就相当于返回一个被拒绝的 Promise 对象。例:
return Promise.resolve(xxx),在后续处理的时候就需要在 then 中接收 resolve 的值,如果函数中抛出错误,那么就相当于返回一个被拒绝的 Promise 对象,需要在 catch 中接收 reject 的值。如果函数中本身没有 return 的内容,那么相当于return Promise.resolve(undefined); - 如果 resolved 成功了,则 await 可以接收到返回的值,如果是 rejected 失败了,则会抛出错误,需要在 catch 中捕获。
# 优势
- 用同步代码的方式编码,简化异步编程的代码逻辑,消除回调地狱和层层嵌套判断等
- 处理同步异步错误更加方便,便于 debug 定位错误的位置,如果使用 then 链式调用,就不容易发现是哪个 then 里面报的错,除非每个 then 后面都加一个 catch 单独处理,否则单凭 try/catch 很难直接捕获发生在 Promise 内部的错误。
# 生成器函数和迭代器对象
执行生成器函数可以获得一个迭代器对象。
# 生成器
即 Generator 函数: 用function*定义函数,可以暂停执行并保存其状态,然后在需要时恢复执行,生成器函数内部使用yield语句来产值,暂停执行并返回一个迭代器对象(值是 yield 后面的值)给调用者,通过迭代器对象的 next 方法可以控制生成器函数的执行。
// 生成器函数
function* generatorDemo(){
yield 1;
yield 2;
yield 3;
}
// 迭代器对象
// 调用生成器函数,返回迭代器对象
const iterator = generatorDemo();
console.log(iterator.next()); // {value: 1, done: false}
console.log(iterator.next()); // {value: 2, done: false}
console.log(iterator.next()); // {value: 3, done: false}
console.log(iterator.next()); // {value: undefined, done: true}
// 模拟异步函数
function* getUserInfo(){
console.log("start getUserInfo");
yield new Promise((resolve, reject) => {
console.log("before setTimeout");
setTimeout(() => {
console.log("before resolve");
resolve({id:1, name: "test"});
console.log("after resolve");
}, 3000)
console.log("after setTimeout");
});
console.log("after yield");
}
console.log("start---");
let it = getUserInfo();
it.next().value.then(param=>console.log("get info ==> ", param));
console.log("finished");
// 输出如下:
start---
start getUserInfo
before setTimeout
after setTimeout
finished
// 过3秒之后再打印如下:
before resolve
after resolve
get info ==> {id: 1, name: 'test'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 迭代器
是一种对象,提供了一种按顺序访问集合元素的方法。有两个核心方法:next()和 return()。next()方法返回一个包含 value 和 done 属性的对象,done 表示迭代是否完成,value 表示当前迭代的值。return()方法用于提前终止迭代。
# 异步编程的实现方式有哪些
- 回调函数
- Promise
- async/await
- 生成器函数和迭代器对象
- 事件监听
- 发布/订阅模式
# 惰性函数
- 惰性函数(Lazy Function)是一种在程序中仅在需要时才执行的函数。这意味着该函数不会立即执行,而是返回一个值(通常是一个函数或一个计算结果)的引用,直到需要这个值时才进行计算。惰性函数的主要目的是优化性能,避免不必要的计算,特别是在处理大型数据集或复杂计算时。
- 用于只需要执行一次的地方,后续可以直接用缓存结果或者初次执行完之后就修改这个函数。(跟上面不是同一个东西)
// 定义一个惰性函数
function lazyValue(x) {
return function () {
console.log("计算中...");
return x * 2; // 计算值
};
}
// 使用惰性函数
const getValue = lazyValue(10);
// 此时并没有进行计算
console.log("函数已创建,但未计算值。");
// 现在需要计算值时,调用返回的函数
const result = getValue(); // 输出 '计算中...',然后返回计算结果
console.log("计算结果:", result); // 输出: 计算结果: 20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 箭头函数
- js 中的作用域包括:全局作用域、函数作用域、块级作用域。
- 箭头函数的作用域是在定义时确定的,基于词法作用域,不会捕获外部的 this 值,而是使用定义时的 this 值。这个 this 值在箭头函数内部是固定的,不会因为外部作用域的变化而改变。
- 箭头函数没有自己的 arguments 对象,它会捕获其所在上下文的 arguments 对象。
- 箭头函数没有自己的构造函数,不能用作构造函数。可以通过
Reflect.construct(Object, [], arrowFunc)来判断是不是箭头函数--箭头函数没有 constructor,不能被 new。 - 判断箭头函数的 this 时,可以观察箭头函数定义的位置以及有没有被函数包裹,如果被函数包裹,那么箭头函数的 this 就是包裹函数的 this,否则就是全局对象(在严格模式下是 undefined)。适用于通过
{name:()=>{...}}这种对象形式定义的属性函数。 - 箭头函数不能被用于构造函数,不能使用 new 关键字实例化。
- 箭头函数不适用于需要使用 this 的场景,如构造函数、事件处理函数、原型链上的方法等。
# 内部方法[[construct]]
[[construct]]是 JS 引擎的一个内部方法,用于创建和初始化对象的实例。不能直接访问,它在 JavaScript 中用于实现构造函数,通过 new 关键字调用创建新对象。- 通过
Reflect.construct(Object, [], func)是否报错,来判断一个函数是否有内部方法[[construct]],如果没有[[construct]]则不能通过 new 来创建实例对象。 - 如果通过 es5 的 function 的形式创建的实例对象的方法上有
[[construct]],可以继续new obj.sayName()来创建对象而不会报错。但是通过 es6 的 class 里面的原型方法上没有[[construct]],不能 new。
// es5
function Person5(name) {
this.name = name;
}
Person.prototype.sayName = function () {
console.log(this.name);
};
// es6
class Person6 {
constructor(name) {
this.name = name;
}
// 原型方法
sayName() {
console.log(this.name);
}
}
let obj5 = new Person5("test5");
let obj6 = new Person6("test6");
// test
console.log(Reflect.construct(Object, [], obj5.sayName)); // 不报错==>true
console.log(Reflect.construct(Object, [], obj6.sayName)); // 报错==>false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# ++
++是一个前缀自增运算符,用于将变量的值增加 1,并返回增加后的值。++在数字前面,会先自增再返回增加后的值。++在数字后面,会先返回当前值,然后再自增。
# function 的 length 属性
function的length属性表示函数的参数个数,不包括默认参数和剩余参数。function的length属性实际指的是函数的第一个有默认值的参数之前(左侧)的参数的个数。例function(a,b,c=3,d,...rest){}的参数的 length 就是 2。
# const 和 Object.freeze()
Object.freeze()只能冻结对象当前层级的属性,如果对象的属性也是一个对象,那么这个对象的属性不会被冻结,可以继续修改。const只是内存地址不能改变,如果是对象的话,其属性的值是可以改变的。- 在 Vue 中,对于不需要实现响应式的对象或不会影响页面重新渲染的对象等,可以通过
Object.freeze()冻结这个对象,可以提高性能,后续可以使用Object.isFrozen()来判断对象是否被冻结。 Object.freeze()冻结的对象,直接=赋值得到的新对象也是被冻结的,深拷贝的对象才是未被冻结的。
# 假值与真值
- 假值:
false、null、undefined、0/-0/0n、NaN、""/''/``(空字符串)、document.all(有条件)。 - 除假值外的都是真值。
# Vue2 中的数组操作
由于
Object.defineProperty无法监听数组内容的变化,所以 Vue2 重写了一部分数组的方法来实现响应式:push/pop/shift/unshift/splice/sort/reverse,我们在 Vue 的数组中调用这几个方法时实际调用的是 Vue2 重写后的方法,而非原生的方法。另外 Vue2 也提供了Vue.set(array, index, newValue)、Vue.delete()这个方法来对数组进行操作,能够实现数组数据的响应式渲染。另外对于数组的操作还可以借助
v-if的特性来实现页面的重新渲染,在操作数组前先把会影响到的数据对应的 dom 视图设置v-if=false,这样 dom 会从页面移除,然后修改数组,操作完后再设置v-if=true,这样可以实现 dom 视图的重新渲染。可以同时借助$nextTick()进行操作处理。还可以使用强制渲染:
vm.$forceUpdate()。这个方法会强制组件重新渲染而不考虑数据是否更新,避开了正常的数据流更新的方法,违反了 Vue 响应式更新的规则,但是可以用于一些特殊场景,比如在某些异步操作中,需要强制组件重新渲染。
# Vue2 和 Vue3 的响应式实现的区别
- vue2 的响应式是通过
Object.defineProperty方法,劫持对象的 getter 和 setter,在 getter 中收集依赖,在 setter 中触发依赖,但是这种方式存在一些缺点:
- 由于是遍历递归监听属性,当属性过多或嵌套层级过深时会影响性能
- 无法监听对象新增的属性和删除属性,只能监听对象本身存在的属性,所以设计了
$set和$delete - 如果监听数组的话,无法监听数组元素的增减,只能监听通过下标可以访问到的数组中已有的属性,由于使用
Object.defineProperty遍历监听数组原有元素过于消耗性能,vue 放弃使用Object.defineProperty监听数组,而采用了重写数组原型方法的方式来监听对数组数据的操作,并用$set和splice方法来更新数组,$set和splice会调用重写后的数组方法。
- Proxy 对象:
- 用于创建一个对象的代理,主要用于改变对象的某些默认行为,Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。
- 使用 Proxy 可以解决 Vue2 中的哪些问题,总结一下:
- Proxy 是对整个对象的代理,而 Object.defineProperty 只能代理某个属性。
- 对象上新增属性,Proxy 可以监听到,Object.defineProperty 不能。
- 数组新增修改,Proxy 可以监听到,Object.defineProperty 不能。
- 若对象内部属性要全部递归代理,Proxy 可以只在调用的时候递归,而 Object.definePropery 需要一次完成所有递归,Proxy 相对更灵活,提高性能。
# Reflect 的作用和意义
- 规范语言内部方法的所属对象,不全都堆放在 Object 对象或 Function 等对象的原型上。
- 修改某些 Object 方法的返回结果,让其变得更合理。
- 让 Object 操作是命令式的,让他们都变成函数行为。
- Reflect 对象的方法与 Proxy 对象的方法一一对应,只要是 Proxy 对象的方法,就能在 Reflect 对象上找到对应的方法。这就让 Proxy 对象可以方便地调用对应的 Reflect 方法,完成默认行为,作为修改行为的基础。也就是说,不管 Proxy 怎么修改默认行为,你总可以在 Reflect 上获取默认行为。
# 2025.1.20
# 小鹏
vue、react、angular 框架的响应式原理
- Vue2:通过 Object.defineProperty() 方法对数据进行劫持,当数据发生变化时,会触发 setter 方法,通知依赖的视图更新。
- Vue3:通过 Proxy 对象代理数据,当数据发生变化时,会触发 Proxy 的 set 方法,通知依赖的视图更新。
- React:通过 Virtual DOM 和 Diff 算法,当数据发生变化时,会重新渲染 Virtual DOM,然后通过 Diff 算法对比新旧 Virtual DOM,找出差异,最后更新差异部分。
- Angular:通过 Zone.js 拦截异步操作,当数据发生变化时,会触发 Angular 的变更检测机制,检测数据变化并更新视图。
react 中 hooks 不能放在 if 判断里的原因
- React 依赖于 Hook 调用顺序来确定每个 Hook 的状态。只要 Hook 的调用顺序在多次渲染之间保持一致,React 就能正确地将内部 state 和对应的 Hook 进行关联。如果 Hooks 的调用顺序在不同的渲染中不一致,React 无法保证为正确的 Hook 分配正确的状态。这会导致状态错位,进而引发难以追踪的错误比如内存泄漏,或者组件的表现与预期不一致。
- 通过在组件顶层调用 Hooks,React 可以在每次渲染中按照一致的顺序调用它们,确保状态管理和副作用处理的正确性和一致性。以便于对组件的行为进行预测和理解。这种设计模式也促进了代码的可读性和可维护性,React Hooks 是为了简化组件逻辑和提高代码可读性而设计的。
- 从生命周期的角度来看,Hook 的生命周期与组件的生命周期是紧密相关的。如果将 Hook 放在 if/循环/嵌套函数中,可能会造成 Hook 的生命周期与组件生命周期不一致,也就是说 Hook 的执行依赖于函数组件的调用顺序和调用次数。在 if/循环/嵌套函数 中调用 Hook,可能会导致它们的调用顺序和次数不一致,从而引发一些奇怪的问题,比如状态不稳定、内存泄漏等。
- 由于 React 的状态更新是异步的,只有当依赖项发生变化时,状态才会被更新。而放在条件或循环中的 Hook,其依赖项可能并不会随着条件的改变而改变,这就可能导致组件无法正确地重新渲染。
- 使用 Hook 应该遵守两条规则:只在最顶层使用 Hook,不要在循环,条件或嵌套函数中调用 Hook。只在 React 函数中调用 Hook(比如 React 的函数组件或自定义 Hook 中),不要在普通的 JavaScript 函数中调用 Hook。
Object.defineProperty 和 Proxy 的区别以及 Proxy 的优势:
- 前者代理对象上的属性,不能监听数组及对象深度变化,后者代理对象本身,可以深度监听数组对象变化,PS:Proxy 也不能自动递归代理嵌套对象。
- 兼容性现代浏览器都支持,大部分场景下 Proxy 性能优于 Object.defineProperty,在大规模简单数据的场景下 Proxy 性能可能不如 Object.defineProperty。因为 Proxy 的代理操作会引入一定的性能开销,而 defineProperty 是直接修改对象的属性描述符,开销较小。但是这个性能差距在大多数场景下是可以忽略的,所以在需要实现更复杂的逻辑控制的情况下,推荐使用 Proxy。
- Proxy 可以拦截并重写多种操作,如 get、set、deleteProperty 等;Object.defineProperty 只能拦截属性的读取和赋值操作。
- Proxy 支持迭代器,可以使用 for...of、Array.from() 等进行迭代;Object.defineProperty 不支持迭代器,无法直接进行迭代操作
- Proxy 可以通过添加自定义的 handler 方法进行扩展;Object.defineProperty 不支持扩展,只能使用内置的 get 和 set 方法拦截
- Proxy 使用 new Proxy(target, handler) 创建代理对象;Object.defineProperty 直接在对象上使用 Object.defineProperty(obj, prop, descriptor)
- Proxy 支持监听整个对象的变化,通过 get 和 set 方法拦截;Object.defineProperty 只能监听单个属性的变化,通过 get 和 set 方法拦截
- Proxy 性能相对较低,因为每次操作都需要经过代理;Object.defineProperty 性能相对较高,因为直接在对象上进行操作
- 通过索引去访问或修改已经存在的元素,Object.defineProperty 是可以拦截到的。如果是不存在的元素,或者是通过 push 等方法去修改数组,则无法拦截。vue2 在实现的时候,通过重写了数组原型上的七个方法(push、pop、shift、unshift、splice、sort、reverse)来解决
看代码说输出,什么是微任务和宏任务,以及它们的执行顺序
- 在创建 Promise 的时候,构造函数中的代码是同步执行的。这意味着在调用 new Promise() 时,传递给 Promise 的执行器函数(executor function)会立即执行。
- Promise 的 then, catch, finally 方法会把它们的回调函数添加到微任务队列中。微任务是在当前事件循环的最后执行,优先级高于宏任务(如 setTimeout、setInterval)。
const promise = new Promise((resolve, reject) => {
console.log(1);
setTimeout(() => {
console.log("TimerStart");
// Promise最初同步代码执行完毕后并未改变状态,仍是pending,直到resolve被调用,Promise状态变为resolved,此时会执行微任务队列中的回调函数,即then中的回调函数。
resolve("success");
console.log("TimerEnd");
}, 0);
console.log(2);
});
// promise.then 注册了一个回调函数,该回调函数会在 Promise 状态变为 resolved 后进入微任务队列。
promise.then((value) => {
console.log(value);
});
console.log(4);
// 1 2 4 TimerStart TimerEnd success
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 手写代码:扁平数组转成树
// 如题:
// input:
// [
// { id: 1, parentId: null },
// { id: 2, parentId: null },
// { id: 3, parentId: 1 },
// { id: 4, parentId: 1 },
// { id: 5, parentId: 3 },
// ]
// output:
// [{
// id: 1,
// parentId: null,
// children: [
// { id: 3, parentId: null, children: [{ id: 5, parentId: null, children: [] }] },
// { id: 4, parentId: null, children: [] },
// ],
// },
// { id: 2, parentId: null, children: [] })
// ];
const transform = (data) => {
const tree = [];
const map = new Map();
for (let node of data) {
// 在map中存储的是对象的引用,而不是对象的值,因此可以修改对象的属性。借助这个特性,我们在外部修改了map中的对象,也会影响到tree中的对象。所以最后从map中拿到的node也是被修改了之后的。这里是为了方便后续操作,将data中的对象转换成map中的对象。同时要注意map中set的是一个新的node,而不是直接set的data中的node,否则会污染data的原始数据。
map.set(node.id, { ...node, children: [] });
}
for (let node of data) {
const { id, parentId } = node;
// 在map中存储的是对象的引用,而不是对象的值,因此可以修改对象的属性。借助这个特性,我们在外部修改了map中的对象,也会影响到tree中的对象。所以最后从map中拿到的node也是被修改了之后的。
const treeNode = map.get(id);
if (!parentId) {
tree.push(treeNode);
} else {
const parentNode = map.get(parentId);
if (parentNode?.children) {
parentNode.children.push(treeNode);
}
}
}
return tree;
};
const nodes = [
{ id: 1, parentId: null },
{ id: 2, parentId: null },
{ id: 3, parentId: 1 },
{ id: 4, parentId: 1 },
{ id: 5, parentId: 3 },
{ id: 6, parentId: 3 },
{ id: 7, parentId: 4 },
];
transform(nodes);
console.log(JSON.stringify(transform(nodes), null, 2));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
前端技术选型怎么做的?
- 项目需求分析:功能需求、性能需求、可扩展性
- 技术栈评估:社区和生态系统、成熟度和稳定性、学习曲线
- 团队能力和经验:现有技能、培训和招聘
- 项目时间和预算:开发周期、成本
- 未来发展和技术趋势:技术趋势、更新和支持
- 实验和原型:原型验证、性能测试
- 反馈和调整:用户反馈、持续监测
Promise.then.then.catch:如果第一个 then 报错了,第二个 then 会执行吗?catch 能捕获到异常吗?throw Error 和 reject 的区别?- 如果第一个 then 报错了,第二个 then 没有第二个参数的话,则不会执行!
- resolve 执行之后是可以在后面继续 return value 或者执行其他代码的!
- 如果多个 then 链式调用并在最后跟了一个 catch,那么任意一个 then 的报错都会被这个 catch 捕获到。catch 会捕获到所有 then 链中的错误,包括异步的错误。
- 如果每个 then 后面都跟一个 catch,那么每个 catch 只会捕获到自己对应的 then 的错误,而不会捕获到其他 then 的错误。
Promise.then.catch.then.catch:如果第一个 then 报错了,第二个 then 会执行吗?两个 catch 都能捕获到异常吗?- 如果第一个 then 抛出错误:
- 异常会被紧接着的第一个 catch 捕获。
- 捕获异常后,链会继续向下执行,下一个 then 会执行。
- 如果后续的 then 中不再抛出错误,那么第二个 catch 将不会被触发。
- 第一个 catch 的行为决定了第二个 then 是否执行:
- 如果 catch 返回一个值,第二个 then 会执行并接收此值。
- 如果 catch 抛出错误,第二个 then 不会执行,而是跳到下一个 catch。
- throw Error 和 reject 的区别:throw Error 是抛出一个同步的错误,而 reject 是抛出一个异步的错误,通常用于 Promise 中。
- 拓展:
- 错误传播:在 Promise 链中,如果在 .then 回调函数中抛出错误,这个错误会被传递到链中下一个 .catch 或者接下来链中的 .then 的第二个参数(如果提供了)中。
- 跳过后续 .then:当错误发生时,Promise 链将跳过所有后续的 .then(前提是后面的 then 都没有定义 reject 函数,才会直到遇到 .catch 为止,否则会被定义了 reject 函数的 then 拦截到这个错误并处理而不会再被 catch 拦截一遍,之后的 then 正常执行),并直接进入 .catch。
- .catch 捕获错误:.catch 会捕获链中上游任何一个 .then 抛出的错误或者 Promise 本身的 reject 状态。
- 如果第一个 then 抛出错误:
new Promise((resolve, reject) => {
resolve("Initial Success");
console.log("test1"); // 会最先被打印出来
})
.then((data) => {
console.log(data); // 输出: Initial Success
throw new Error("Something went wrong in first then");
console.log("test2"); // 不会打印
})
.then(
(data) => {
// 这个不会被执行,因为前一个 then 抛出了错误
console.log("This will not be logged:", data);
return "Success in second then";
},
(err) => {
// 如果定义了reject函数,那么会执行这个函数,如果这个函数返回了值,那么这个值会被传递给下一个then的resolve函数。
console.log("This is 2nd then reject err:", err);
return Promise.resolve("from 2nd then reject");
}
)
.then(
(res) => {
console.log("this is 3rd then resolve", res);
},
(err) => {
console.log("this is 3rd then reject", err);
}
)
.catch((error) => {
// 这里会捕获到第一个 then 中抛出的错误
console.error("Caught an error:", error.message); // 输出: Caught an error: Something went wrong in first then
});
// 输出如下:
// Initial Success
// This is 2nd then reject err: Error: Something went wrong in first then at <anonymous>:6:11
// this is 3rd then resolve from 2nd then reject
new Promise((resolve, reject) => {
resolve("Initial Success");
})
.then((data) => {
console.log(data); // 输出: Initial Success
throw new Error("Something went wrong in first then");
})
.then((data) => {
// 这个不会被执行,因为前一个 then 抛出了错误
console.log("This will not be logged:", data);
return "Success in second then";
})
.then(
(res) => {
console.log("this is 3rd then resolve", res);
},
(err) => {
// 这里会执行!
console.log("this is 3rd then reject", err);
}
)
.catch((error) => {
// 这里会捕获到第一个 then 中抛出的错误
console.error("Caught an error:", error.message); // 输出: Caught an error: Something went wrong in first then
});
// 输出如下:
// Initial Success
// this is 3rd then reject Error: Something went wrong in first then at <anonymous>:6:11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
有一个页面加载大量图片,怎么做性能优化?页面多图片加载优化?
- 懒加载(Lazy Loading):对于图片来说,可以使用原生的
loading="lazy"属性,或使用懒加载库,如 lazysizes,来实现这一点。这样可以显著减少初始加载时间。 - 使用响应式图片:根据设备的不同分辨率,提供不同大小的图片,以减少不必要的带宽消耗。可以使用 srcset 和 sizes 属性来实现。
- 图像压缩与格式优化:压缩图片:使用工具(如 TinyPNG、ImageOptim 等)压缩图片文件。选择合适的格式:对于高质量的图像,使用 JPEG;对于透明背景,使用 PNG;使用 WebP 格式可以达到更好的压缩效果。
- 使用内容分发网络(CDN):通过 CDN 分发图片,减少服务器负载,并加快加载速度,因为 CDN 会选择离用户最近的服务器提供资源。
- 利用浏览器同个域名最多建立 6 个 http 请求的特性,使用不同的 CDN 域名,可以提高并发请求数量。
- HTTP2:多路复用,一个链接就可以并行请求多张图片,减少加载时间。
- 预加载关键图像:对于首屏需要立即展示的图片,可以使用
<link rel="preload">标签来提前加载,确保它们在页面加载时立即可见。 - 精灵图(CSS Sprites):将多个小图片合并成一张大图片,通过 CSS 显示不同的部分,减少 HTTP 请求数量。
- 延迟加载非关键内容:对于不影响首屏显示的图片,如页面底部的图片,可以延迟加载。用户滚动到图片所在位置时再加载这些图片。
- 使用 Intersection Observer:利用浏览器的 Intersection Observer API 可以高效地实现懒加载,监控图片何时进入视口,并在需要时加载它们。
- 优化缓存策略:为图片设置合适的缓存头,确保用户在后续访问时可以直接从缓存中加载图片,而不是重新下载。
Cache-Control: max-age=31536000。 - 硬件加速:使用 CSS 的
transform: translate3d(0, 0, 0);、opacity、will-change: transform, opacity;属性进行硬件加速,可以提高页面渲染性能。 - 前端硬件加速的使用场景:CSS 动画、3D 加载、视频播放、WebGL 渲染、Canvas 绘图、SVG 动画等。使用
<canvas>标签时,可以选择 2D 上下文或 WebGL 上下文。WebGL 是基于 GPU 的绘图 API,可以直接触发硬件加速。const gl = canvas.getContext('webgl'); // 获取 WebGL 上下文 - Web 动画 API:硬件加速动画
<div id="box"></div> <script> const box = document.getElementById("box"); box.animate([{ transform: "translateX(0)" }, { transform: "translateX(300px)" }], { duration: 1000, iterations: Infinity, }); </script>1
2
3
4
5
6
7
8
9- 使用
<video>标签播放视频时,现代浏览器会自动利用 GPU 加速视频解码。HTML5 视频播放默认支持硬件加速,只需使用<video>标签即可。
- 懒加载(Lazy Loading):对于图片来说,可以使用原生的
性能优化看哪些指标?
页面加载时间:
- Time to First Byte (TTFB): 从用户请求到接收到第一个字节所需的时间,反映了服务器的响应速度。
- First Contentful Paint (FCP): 页面上的第一个文本或图像内容绘制在屏幕上的时间。
- Largest Contentful Paint (LCP): 页面主内容加载完成的时间,反映了页面的可用性。
- TBT:
- TTI:首次可交互时间,反映用户与页面的交互响应速度。
- FP:页面首次绘制的时间,反映用户与页面的交互响应速度。
- FMP:
- DOMContentLoaded:DOM 加载完成时间,反映页面的加载速度。
- 首次可交互时间:用户与页面的交互响应速度。
- 首次可点击时间:用户与页面的交互响应速度。
- CSS 两列布局:左侧固定右侧自适应:float、flex、grid、position 等等
<div class="container">
<div class="left">左侧</div>
<div class="right">右侧</div>
</div>
2
3
4
/* 1. float */
.container {
width: 100vw;
height: 100vh;
overflow: hidden;
background: yellowgreen;
}
.left {
float: left;
width: 200px;
background: red;
}
.right {
width: calc(100% - 200px);
margin-left: 200px;
background: grey;
}
/* 2. position */
.container {
position: relative;
width: 100vw;
height: 100vh;
background: yellowgreen;
}
.left {
position: absolute;
left: 0;
top: 0;
width: 200px;
height: 100%;
background: red;
}
.right {
/* width: calc(100% - 200px); */
margin-left: 200px;
background: grey;
}
/* 3. flex */
.container {
display: flex;
width: 100vw;
height: 100vh;
background: yellowgreen;
}
.left {
width: 200px; /* 左侧固定宽度 */
background: red;
}
.right {
flex: 1; /* 右侧自适应 */
background: grey;
}
/* 4. grid */
.container {
display: grid;
grid-template-columns: 200px 1fr; /* 左侧固定宽度,右侧自适应 */
width: 100vw;
height: 100vh;
background: yellowgreen;
}
.left {
background: red;
}
.right {
background: grey;
}
/* 5. table */
.container {
display: table;
width: 100%; /* 占满父级宽度 */
}
.left {
display: table-cell;
width: 200px; /* 左侧固定宽度 */
background: red;
}
.right {
display: table-cell;
background: grey; /* 右侧自适应 */
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
flex:1的含义及默认值:flex-grow:1;flex-shrink:1;flex-basis:0%;(Chrome)- 同理:
flex:0==>flex-grow:0;flex-shrink:1;flex-basis:0%;(Chrome) - 同理:
flex:auto==>flex-grow:1;flex-shrink:1;flex-basis:auto;(Chrome)
- 同理:
# 2025.3.5
# 药明笔试
- 处理 tweet 时间事件
- 没读懂题目
- 数组中相同数字出现的最多的次数称为数组的度,要求找出满足和该数组的度相同的子数组的最小长度
- 遍历找出数组的度,然后记录相应的数字第一次和最后一次出现的位置,计算出子数组的长度,找出最小的子数组长度
- SQL:从部门表和职员表中找出薪资最高的职员并合并成一张新的表
SELECT e.department_id AS Department, e.name AS Employee, e.salary AS Salary FROM employees e JOIN departments d ON e.department_id = d.department_id ORDER BY e.salary DESC LIMIT 1
- Shell:只输出一个文件的第十行的内容
- 用
sed命令:sed -n '10p' filename - 用
awk命令:awk 'NR==10' filename - 用
head和tail命令:head -n 10 filename | tail -n 1 - 用
cat和sed命令:cat filename | sed -n '10p' - 用
cat和awk命令:cat filename | awk 'NR==10' - 用
cat和head和tail命令:cat filename | head -n 10 | tail -n 1 - 用
cat和sed和awk命令:cat filename | sed -n '10p' | awk '{print}'或cat filename | awk 'NR==10' | sed -n '1p'
- 用
# 3.8
# 日本
原型和原型链
new 一个对象的时候发生了什么,如果 return 了一些东西会发生什么?
- 创建一个新对象:当你使用 new 关键字时,会创建一个全新的对象。这个对象的原型会被设置为构造函数的原型对象(Constructor.prototype)。
- 执行构造函数:然后 JavaScript 会执行构造函数内的代码。构造函数中的 this 关键字将指向新创建的对象。在这个函数中,通常会初始化对象的属性和方法。
- 返回对象:
- 如果构造函数没有显式返回值:JavaScript 默认会返回新创建的对象。
- 如果构造函数显式返回一个对象:则会返回该对象,而不是默认返回的新对象。
- 如果返回的是基本类型(如字符串、数字、布尔值等)或不返回任何东西:则无论如何,都会返回新创建的对象。
原型链继承和构造函数继承的区别
- 原型链继承是通过将子类的原型指向父类的实例来实现的。子类可以访问父类实例的属性和方法。
- 构造函数继承是通过在子类构造函数内调用父类构造函数来实现的。这种方式可以将父类的属性复制到子类的实例中。
特性 原型链继承 构造函数继承 属性继承 只继承父类的原型属性 继承父类的实例属性 方法继承 通过原型共享方法,所有实例共享同一个方法 每个实例都有自己的方法副本 构造函数参数 无法向父类构造函数传递参数 可以向父类构造函数传递参数 多重继承 不支持多重继承 也不支持多重继承 实例共享 所有子类实例共享父类的属性 每个子类实例都拥有自己的属性副本 性能 更节省内存,但方法共享可能导致状态不一致 占用更多内存,但每个实例都有独立的状态 - 寄生组合继承可以结合二者的优点:使用构造函数继承实例属性,同时使用原型链继承共享方法。在构造函数中调用父类构造函数来继承属性,并使用
Object.create()来建立原型链。这样,结合两者的优点,就能更好地实现 JavaScript 中的继承。
setState 是同步的还是异步的,在 16 和 18 版本的区别
- 一般来说是异步的,但实际上是由于 react 的批处理机制合并多次 setState 为一次更新导致的,在 setTimeout 中就是同步的,多次调用就会导致多次渲染(react16),在 react18 版本中做了修改,在 setTimeout 中多次调用也会合并成一次更新了。也可以使用
useTransitionHook,用于处理并发状态更新。React 18 引入了并发渲染的能力,新的 startTransition API 允许开发者指定某些状态更新为“过渡”,从而改善用户体验。这个特性对 setState 的使用有直接影响。使用 startTransition 可以标记一些非紧急的更新,这样 React 就可以优先处理用户的输入,确保界面的响应性。通过这种方式,可以让 React 更好地管理状态更新的优先级,提高复杂应用的性能和响应性。
import { startTransition } from "react"; startTransition(() => { setState({ count: count + 1 }); }); const [isPending, startTransition] = useTransition(); const handleClick = () => { startTransition(() => { setState({ count: count + 1 }); }); };1
2
3
4
5
6
7
8
9
10
11
12
13- 在 React 18 中,批处理的行为得到了进一步增强,支持在异步事件和 Promise 中自动批处理。这意味着即使是在异步操作中(比如在 setTimeout 或 Promise 的回调中),setState 的多次调用也可以被合并。这种增强使得在处理复杂状态更新时更加高效,减少了不必要的渲染。
- 在 React 18 中,useState 允许接受一个函数作为初始值,这对某些性能敏感的情况特别有用,确保初始状态只计算一次:
const [state, setState] = useState(() => { const initialValue = computeInitialValue(); // 只在初始渲染时调用 return initialValue; });1
2
3
4- 一般来说是异步的,但实际上是由于 react 的批处理机制合并多次 setState 为一次更新导致的,在 setTimeout 中就是同步的,多次调用就会导致多次渲染(react16),在 react18 版本中做了修改,在 setTimeout 中多次调用也会合并成一次更新了。也可以使用
TS 泛型,是怎么做类型守卫的实现的?
- 泛型是一种允许在定义函数、类或接口时不指定具体类型,而是在使用时再指定的技术。它可以提高代码的灵活性和可复用性。例如,定义一个接受任意类型的数组的函数。
- 类型守卫是 TypeScript 中一种用于缩小变量类型范围的机制。它可以在运行时检查变量的类型,并且能够使 TypeScript 编译器更准确地推断变量的类型。
- 在 TypeScript 中,泛型守卫(Generic Guards)是一种用于在泛型代码中进行类型检查的技术。泛型守卫可以帮助你在使用泛型时,精确地推断出变量的具体类型,从而确保在编写代码时能够获得更好的类型安全和更准确的类型推断。
- 类型守卫是 TypeScript 中的一种机制,用于在运行时检查某个变量的类型,从而使 TypeScript 能够推断出该变量的具体类型。类型守卫的常见形式包括:
- typeof 检查:用于检查基本数据类型。
- instanceof 检查:用于检查对象的类型。
- 用户自定义类型守卫:通过返回类型为 arg is Type 的函数来实现。
- 在 TypeScript 中,主要的概念是 类型守卫(Type Guards)。而 泛型守卫 并不是一个正式的术语,但可以理解为在泛型上下文中使用类型守卫来进行类型判断和推断的技术。因此,实际上 TypeScript 只有类型守卫这一种机制,而泛型守卫是特指使用泛型时的类型守卫。
// typeof function log(value: string | number) { if (typeof value === "string") { console.log(value.toUpperCase()); // value 是 string } else { console.log(value.toFixed(2)); // value 是 number } } // instanceof class Dog { bark() { console.log("Woof!"); } } class Cat { meow() { console.log("Meow!"); } } function handlePet(pet: Dog | Cat) { if (pet instanceof Dog) { pet.bark(); // pet 是 Dog } else { pet.meow(); // pet 是 Cat } } // 自定义类型守卫 interface Dog { bark: () => void; } interface Cat { meow: () => void; } function isDog(pet: Dog | Cat): pet is Dog { return (pet as Dog).bark !== undefined; } function handlePet(pet: Dog | Cat) { if (isDog(pet)) { pet.bark(); // pet 是 Dog } else { pet.meow(); // pet 是 Cat } } // 泛型结合类型守卫 function isArray<T>(arg: T): arg is T[] { return Array.isArray(arg); } function processValue<T>(value: T) { if (isArray(value)) { console.log(`Array with length: ${value.length}`); // value 是 T[] } else { console.log(`Single value: ${value}`); // value 是 T } } processValue([1, 2, 3]); // 输出: Array with length: 3 processValue(10); // 输出: Single value: 101
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63看代码说输出:var 和 let 的区别,宏任务微任务,TS 的 interface 和 type 的区别
用没用过自定义 hooks
项目中怎么做的权限控制
# ebay 外包
// 请实现一个异步任务调度器,可以控制同时运行的异步任务数量。
// 要求
// * 构造一个 Scheduler 类,并实现 add 方法添加异步任务,每个任务返回一个 Promise。
// * Scheduler 每次只能执行两个异步任务,当一个任务完成后,下一个任务才能开始执行。
// * add 方法应返回一个 Promise,任务完成后该 Promise 将被 resolve
class Scheduler {
constructor() {
this.tasks = [];
this.count = 2;
this.taskNum = 0;
}
add(task) {
this.tasks.push(task);
const start = () => {
return new Promise(async (resolve) => {
if (!this.tasks.length) return;
if (this.taskNum >= this.count) return;
const task = this.tasks.shift();
try {
this.taskNum++;
await task();
this.taskNum--;
resolve();
} catch (e) {
console.log(e);
} finally {
start();
}
});
};
start();
}
}
const timeout = (time) => new Promise((resolve) => setTimeout(resolve, time));
const scheduler = new Scheduler();
const addTask = (time, name) => {
scheduler.add(() => timeout(time).then(() => console.log(name)));
};
addTask(1000, "A"); // Output A after 1s
addTask(500, "B"); // Output B after 0.5s
addTask(300, "C"); // After task A or B is completed, output C after 0.3s
addTask(400, "D"); // After task C is completed, output after 0.4s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49